Tutorial: Classifier app on Expanse HPC
Topics
- Creating a Batch Application on a HPC system
- Application overview
- Step 1: Accessing the application creation page
- Step 2: Set the status
- Step 3: Provide app details
- Step 4: Select app type
- Step 5: Miscellaneous settings
- Step 6: Select container runtime
- Step 7: Batch scheduler
- Step 8: Container image setup
- Step 9: System selection
- Step 10: Input Type Configuration
- Step 11: Configure Resource Limits
- Step 12: Finalize and save
- Step 13: Creating Input Element
- Step 14: Monitoring job status
- Step 15: Cloning and re-submitting jobs
Creating a Classifier Batch Application on a HPC system ↑
This tutorial will walk you through the steps of creating an application to run on a Expanse cluster using the provided web interface. Follow the instructions below to complete each section of the form.
Application overview ↑
The image classify application allows you to perform image classification using TensorFlow on the Expanse cluster.
Once you submit a job, image classify handles everything automatically. The input files you provide during the submission are staged, and the classification process is triggered. You can then find the results in the designated output directory.
To classify an image, simply pass the image file through the command line using the --image_file argument. In order to test the application using the singularity image, run a command like this:
singularity run /home/qwxdev/apps/img-classify.sif --image_file=https://s3.amazonaws.com/cdn-origin-etr.akc.org/wp-content/uploads/2017/11/09152345/Alaskan-Malamut…;
This will classify the image found at the given URL, which is a JPEG of an Alaskan Malamute. If everything works correctly, you should see the classification results as output in the job output directory.
Step 1: Accessing the application creation page ↑
- Login to https://qwx1.onescienceway.com.
- Navigate to the “Apps” menu, https://qwx1.onescienceway.com/node/add/tapis_app and click on "Add app".
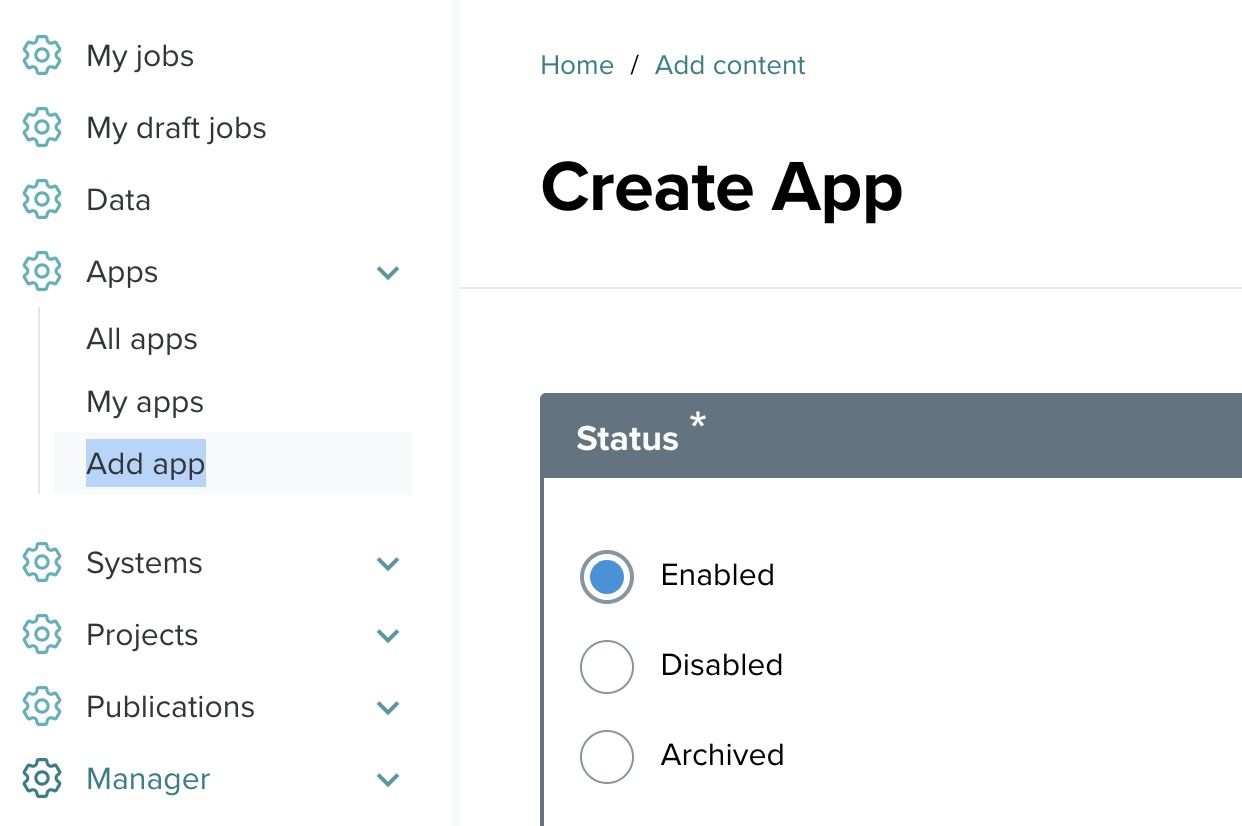
Step 2: Set the status ↑
Under the Status section, you will find three options:
- Enabled: Select this if the application should be available for use.
- Disabled: Select this to disable the app.
- Archived: Choose this if you want to archive the app but still retain its details for future use.
Select the appropriate status for your application. For this tutorial, choose Enabled.

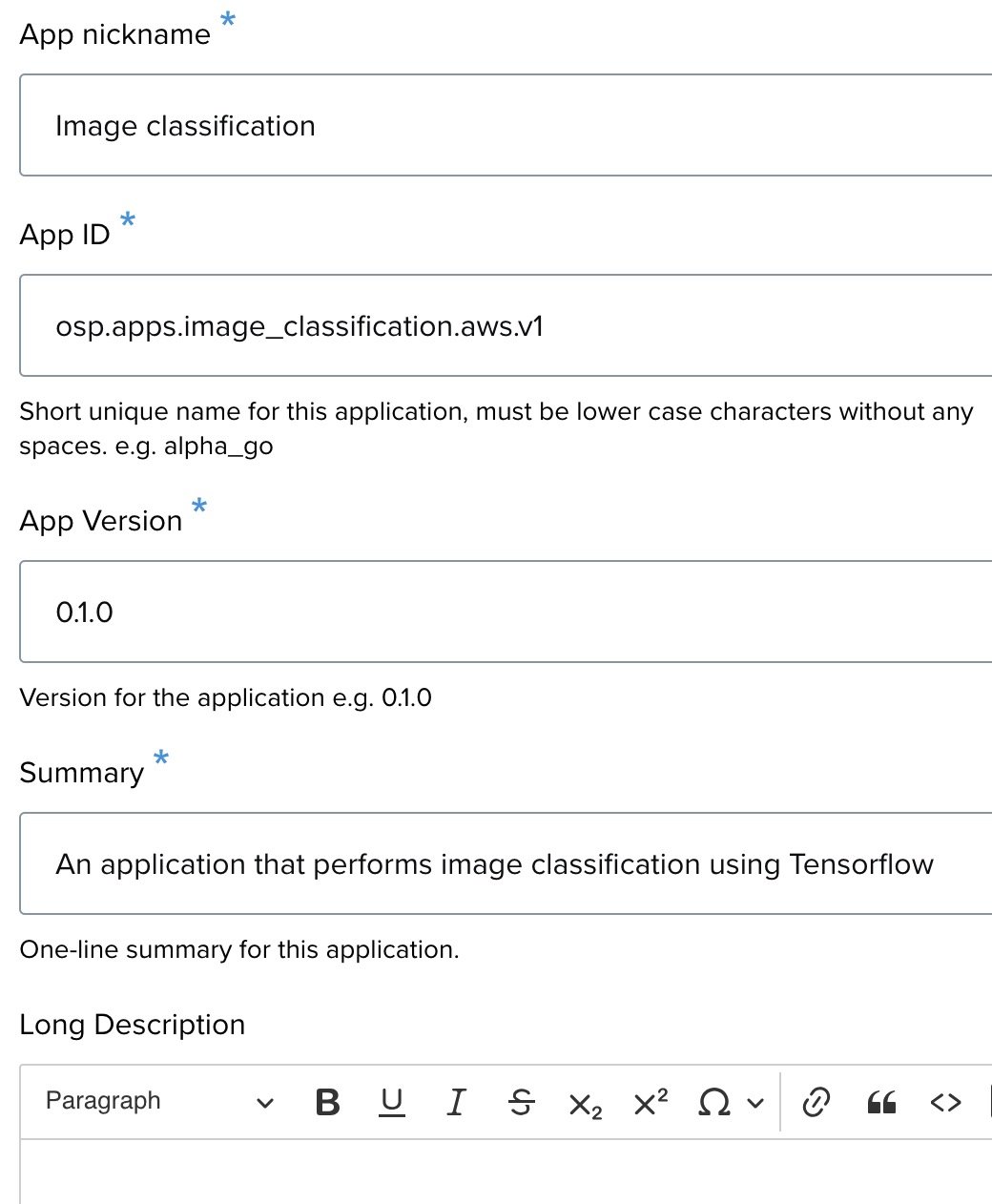
Step 3: Provide app details ↑
In this section, you need to fill in the following fields:
- App nickname: Enter a short nickname for the application. This is a required field.
- App ID: Provide a unique ID for the app. It must be in lowercase and without any spaces. For this tutorial, use your user ID. (e.g., <your user ID>.apps.image_classification.expanse.1).
- App Version: Specify the version of the app (e.g., 0.1.0).
- Summary: Add a one-line summary that describes the application.
- Long Description: You can include a detailed description of your app in this section using the rich text editor.
Step 4: Select app type ↑
In this section, choose the type of application from the following options:
- Batch: Select this if your app runs as a non-interactive command line application.
- VNC: Choose this for interactive graphical applications like MetaLab.
- Web: Use this for interactive web applications like Jupyter Notebook.
For this tutorial, select the option, Batch.

Step 5: Miscellaneous settings ↑
- Restartable: Check this box if the job can be restarted by the user after submission.
- Show generated command: Displays the command in the message window for troubleshooting.
- Update the app’s webform: If checked, this will update the app settings with the values from the form.

Step 6: Select container runtime ↑
Next, choose the runtime that will be used by the application. The available options are:
- Docker
- Singularity
- If this is chosen, additional runtime options like Singularity start or Singularity run become available.
- Executable
- If this is chosen, specify the Executable path to point to the location where the script or binary resides.
For this tutorial, the app uses the singularity container, select Singularity, and Singularity run.

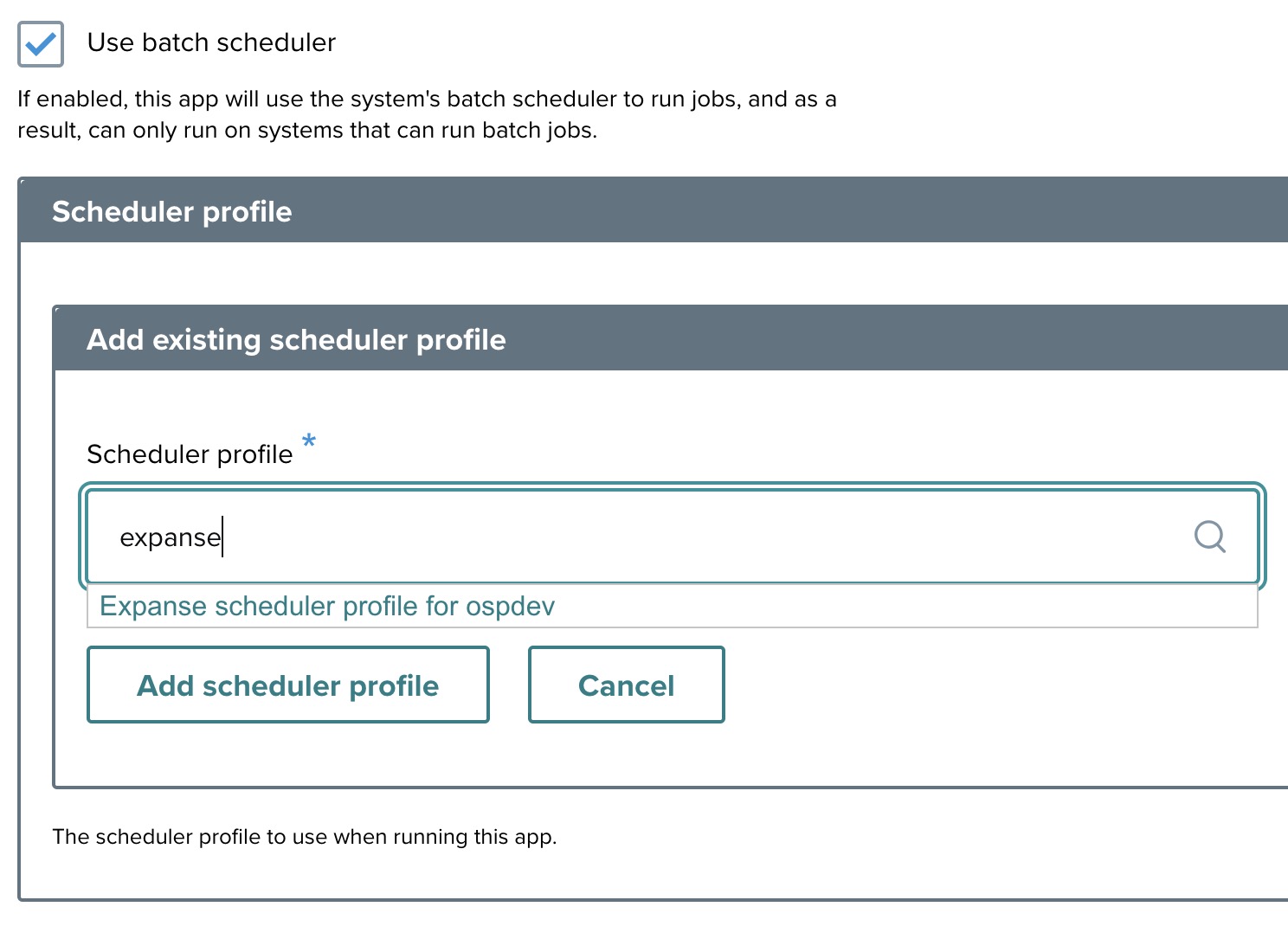
Step 7: Batch scheduler ↑
- Use batch scheduler: Check this box if the app requires a batch scheduler like SLURM.
- If the app uses a batch scheduler, enable this option and add scheduler profiles.
For this tutorial, use the existing scheduler profile, find the keyword, expanse in the search box, and then add it into this application.
Step 8: Container image setup (For Docker or Singularity runtime) ↑
This section is crucial for defining how your application will be packaged and deployed within a container.
- Container image source:
- Public image name: Provide a publicly-accessible container image: Select this if your application's container image is readily available from a public container registry (like Docker Hub). You'll need to provide the full image name (including repository and tag) in the "Container Image URI" field below.
- Container image URI:
- This field is where you specify the exact location or identifier of the container image.
- If you chose "Public image name" above, enter the full image name here (e.g., ubuntu:latest, tensorflow/tensorflow:2.5.0).
- If you uploaded a source code archive or a pre-built image, this field might be auto-populated or you might receive further instructions on how to reference the image.
For this tutorial, select the option, Public image, and put the image URI, /home/qwxdev/apps/img-classify.sif.

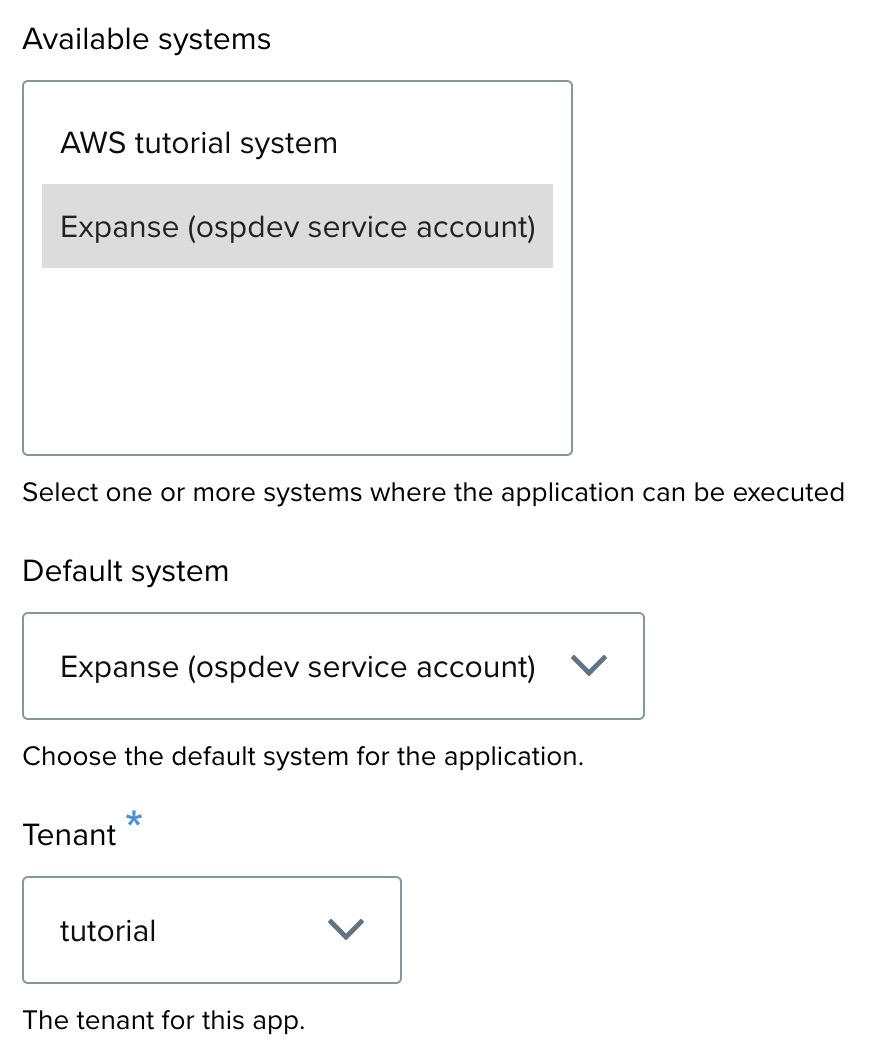
Step 9: System selection ↑
- Available systems: Select the system(s) where the app can be executed. For example, you can choose ”Expanse service”.
- Default system: Choose the default system for the application.
- Tenant: Select a tenant from the dropdown.
For this tutorial, select the option for Available systems and Default system, Expanse service, and select the Tenant, Quakeworx.
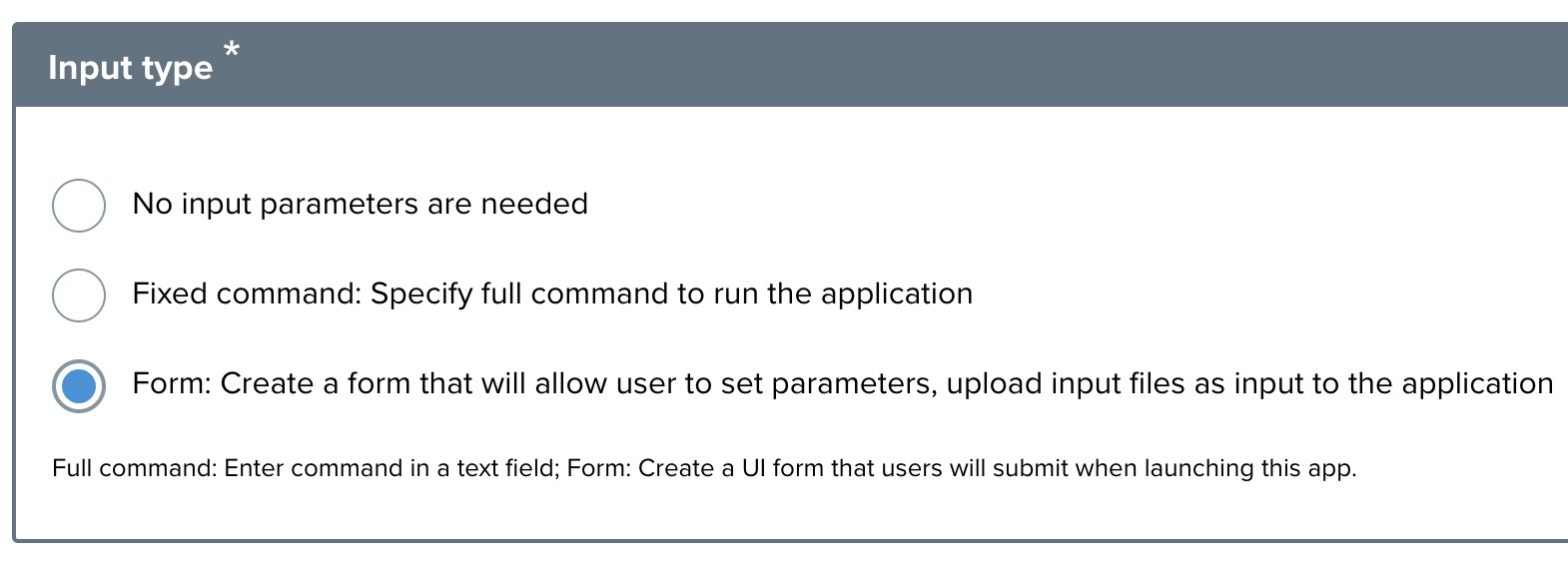
Step 10: Input Type Configuration ↑
Define how inputs will be provided to the app:
- No input parameters are needed: Select this if your application doesn't require any user-provided input.
- Fixed Command: Specify the full command to run the application: Choose this if you want to provide a specific command that will be executed when the application launches. You'll enter the command in the text field that appears.
- Form: Create a form that will allow users to set parameters, upload files as input to the application: Select this option to create a user interface where users can input parameters or upload files when they launch the application.
For this tutorial, users can input parameters, select Form and provide the necessary configuration.
Step 11: Configure Resource Limits ↑
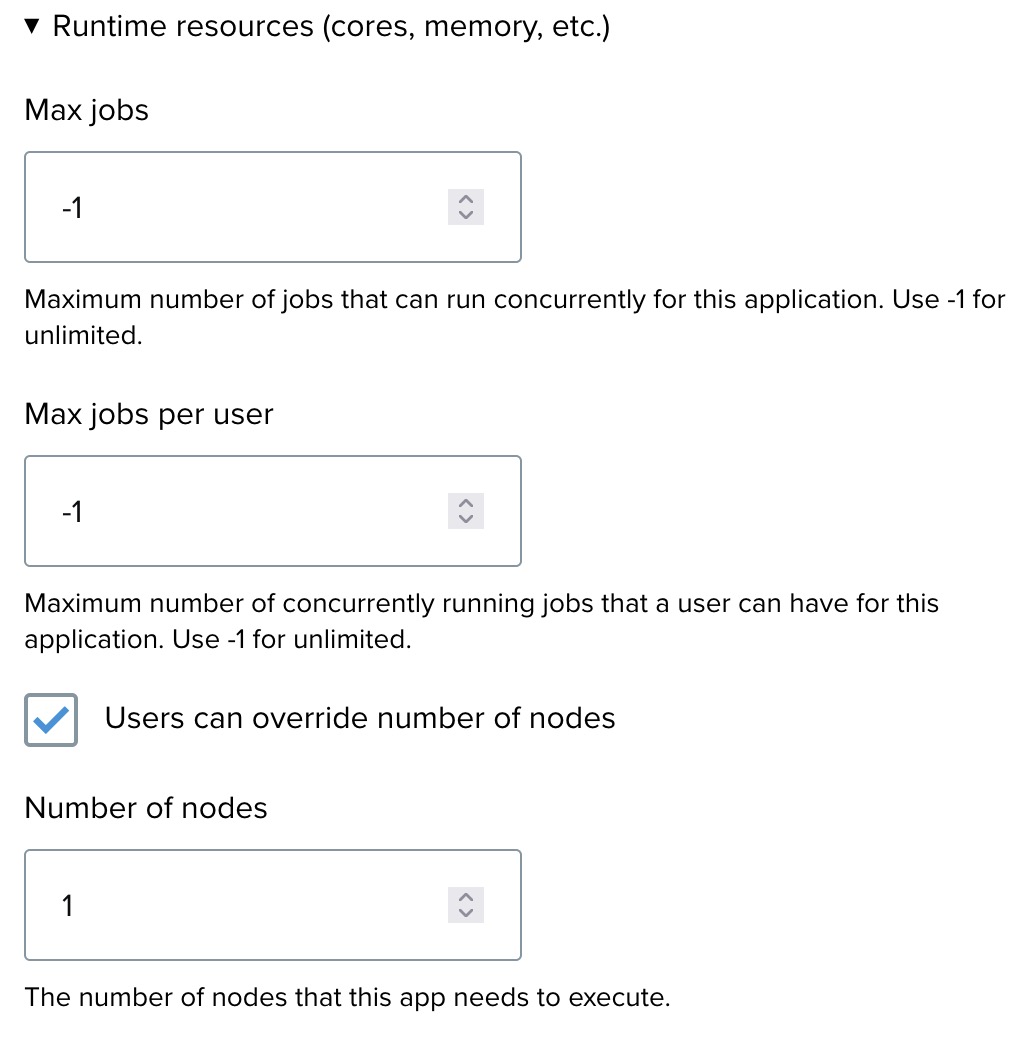
Now, configure the resource limits for the application:
- Max jobs: Set the maximum number of jobs that can run concurrently for this application.
- Max jobs per user: Define the maximum number of jobs one user can run simultaneously.
- Number of nodes: Specify the number of nodes your application requires for execution. If your app is parallelized, users can override this value. You can allow users to override the number of nodes.
- Cores per node: Define how many CPU cores per node will be assigned to this app. You can allow users to override cores per node.
- Memory: Define the amount of memory required for the app, with an option to allow users to override this value. (e.g., 1000 MB).
- Max runtime: Specify the maximum runtime for the app and give users the ability to override this if necessary (e.g., 10 minutes).
For this tutorial, enter 1000 MB in the Memory field required for this app to run.

Step 12: Finalize and save ↑
- After completing the form, review all the details to ensure correctness.
- Click on the Save button to register the application.
Step 13: Creating Input Element ↑
This process is important if you want to collect specific input data from users running your scientific application on a HPC cluster. The following instructions will guide you through the process using the web interface shown in the images.
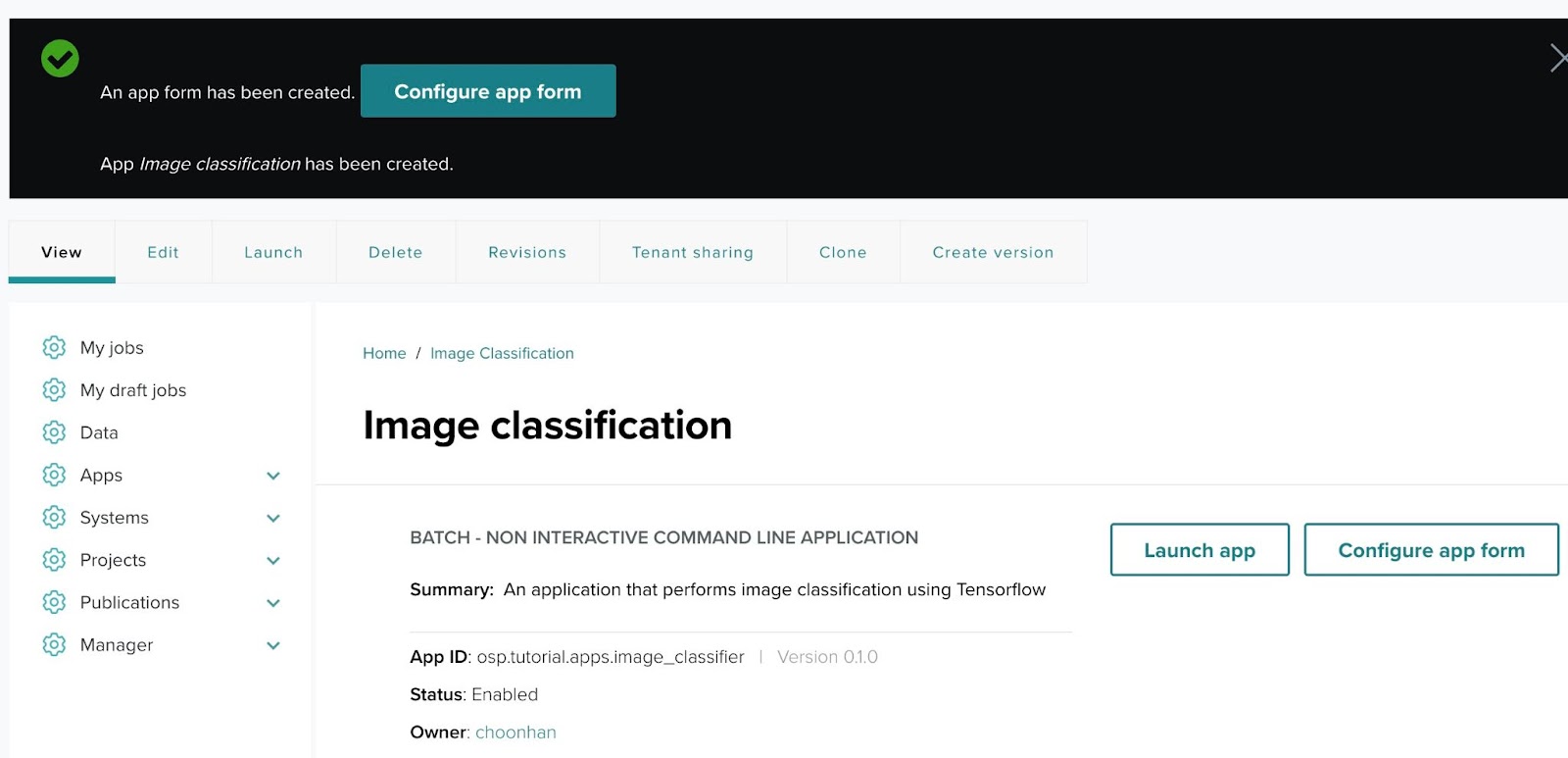
Step 13-1: Application created ↑
Once you have successfully created an application, you will see a confirmation message:
"An app form has been created. App Image classification has been created."
Click the "Configure app form" button to start setting up the custom input elements that your app will require. The app will be configured to accept user inputs necessary for running the scientific application on a designated system (such as a HPC cluster or AWS).
Step 13-2: Begin configuring the app form ↑
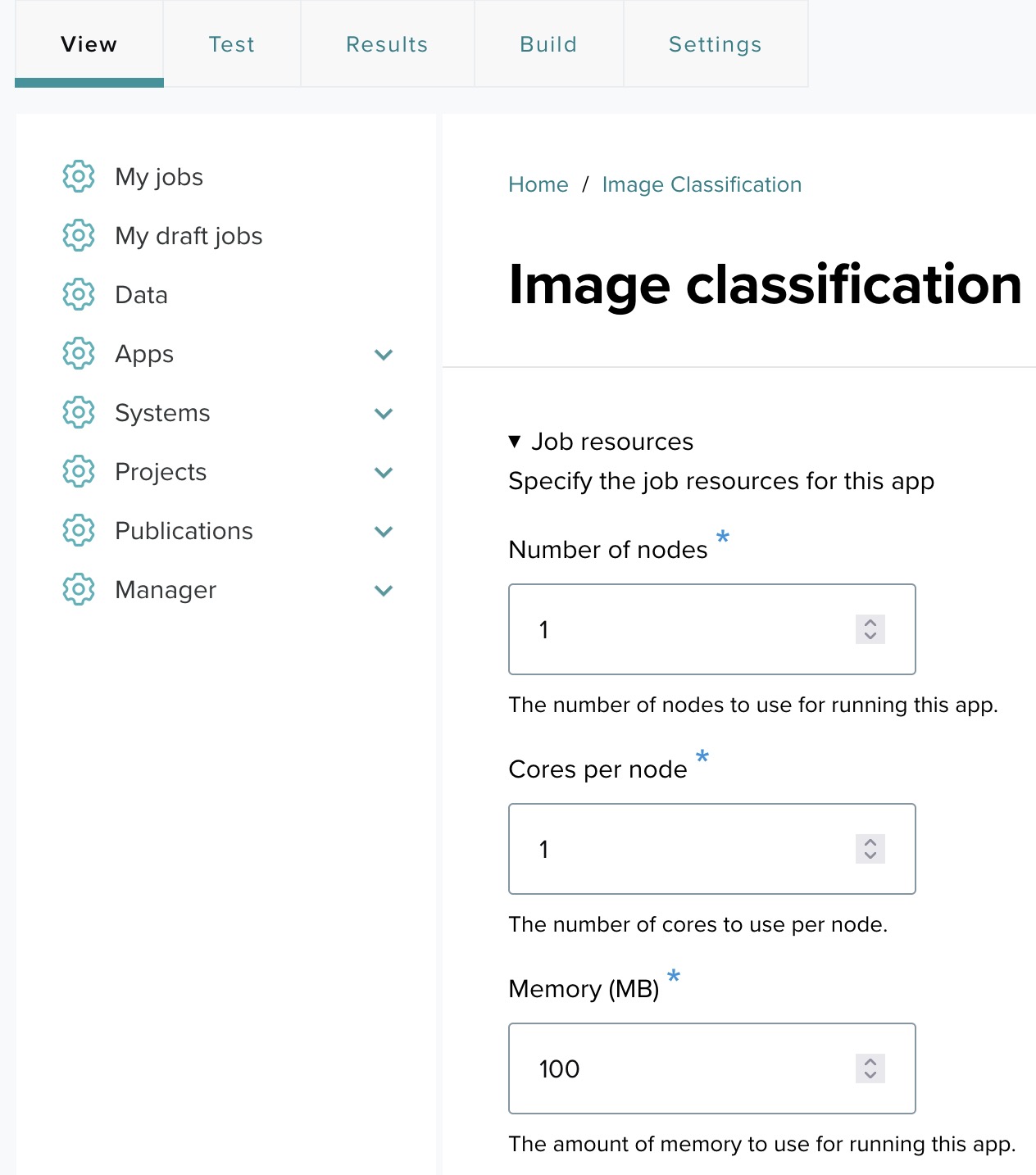
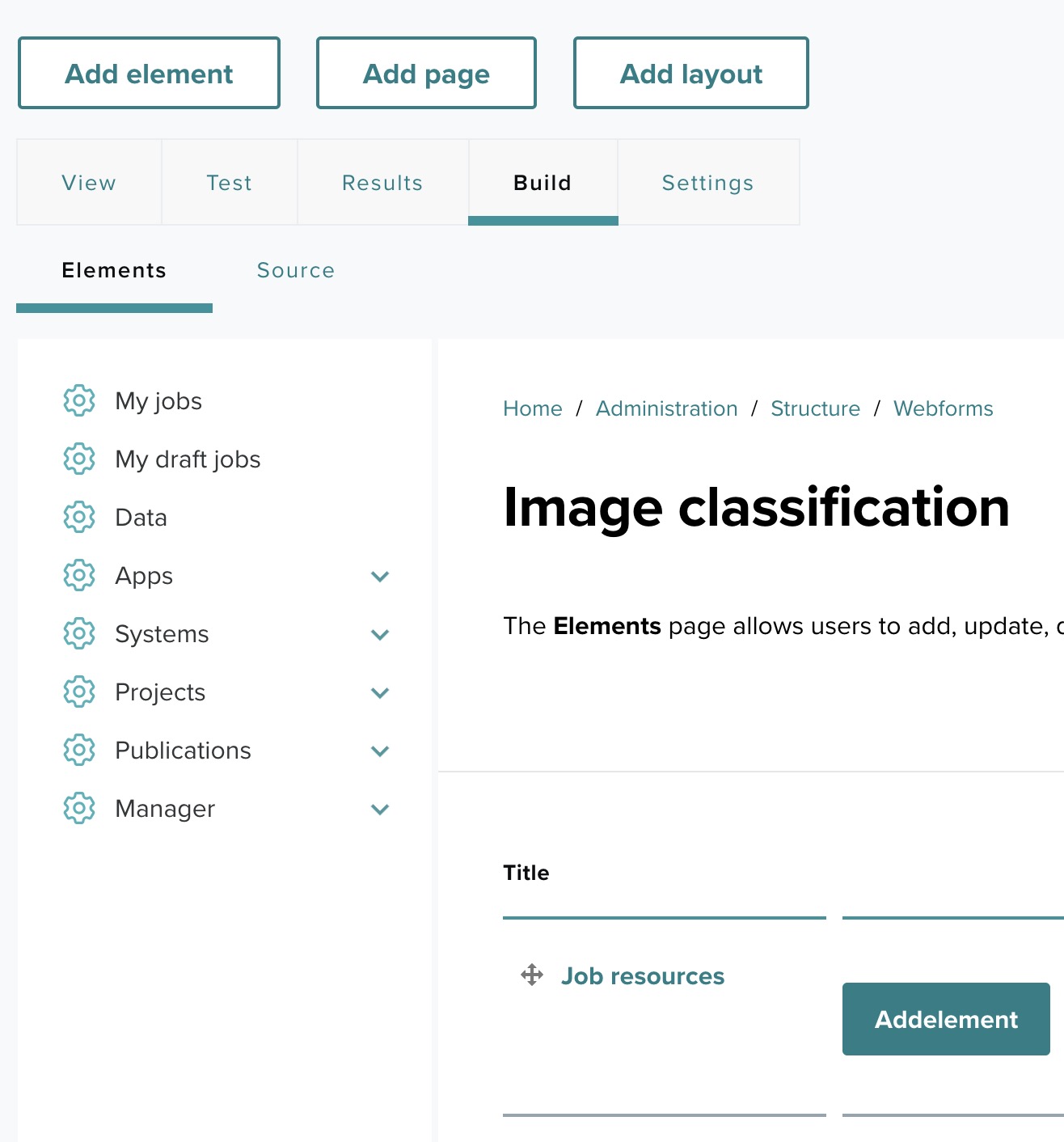
After clicking "Configure app form", you will be directed to a page where you can specify job resources and add input fields for your application. In this case, we are working with an Image classification application as an example.
Step 13-3: Search for elements ↑
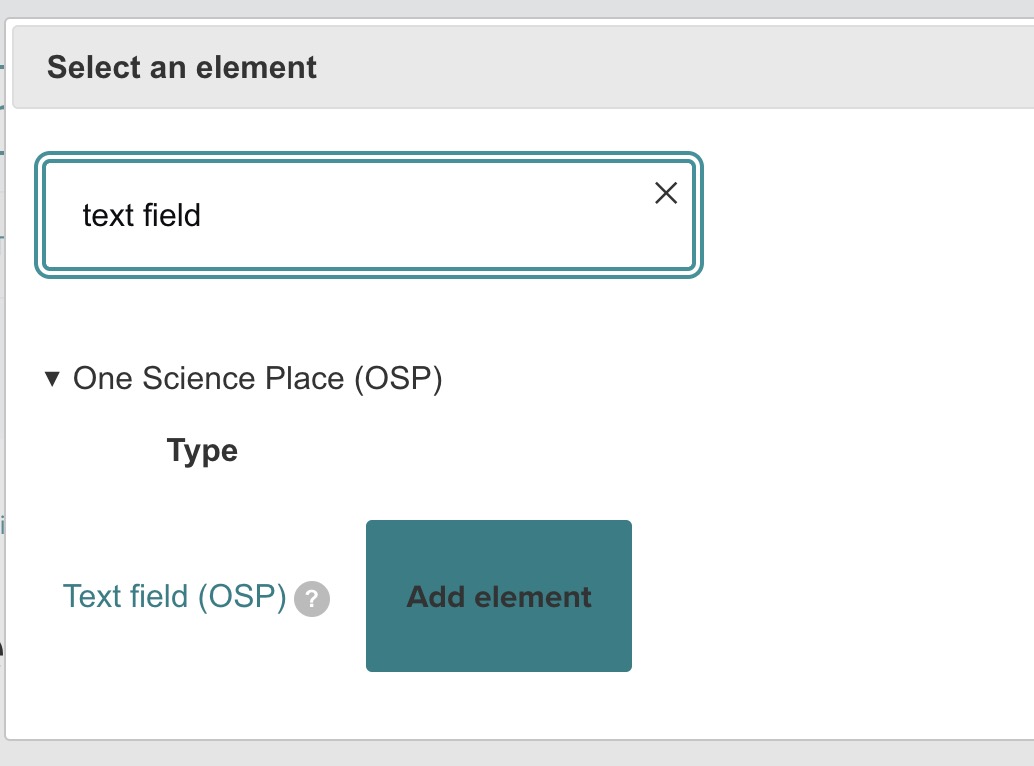
After clicking the Build link, to add a custom input field, such as a URL for the image in this example, follow these steps:
- Select the Add element button on the top left.
- In the Select an element search box, type a keyword related to the input you need. For example, if you need a text field, you can search for the "text field".
- From the list, choose the desired element. In this example, the Text field (OSP) element is chosen to capture the image_url.
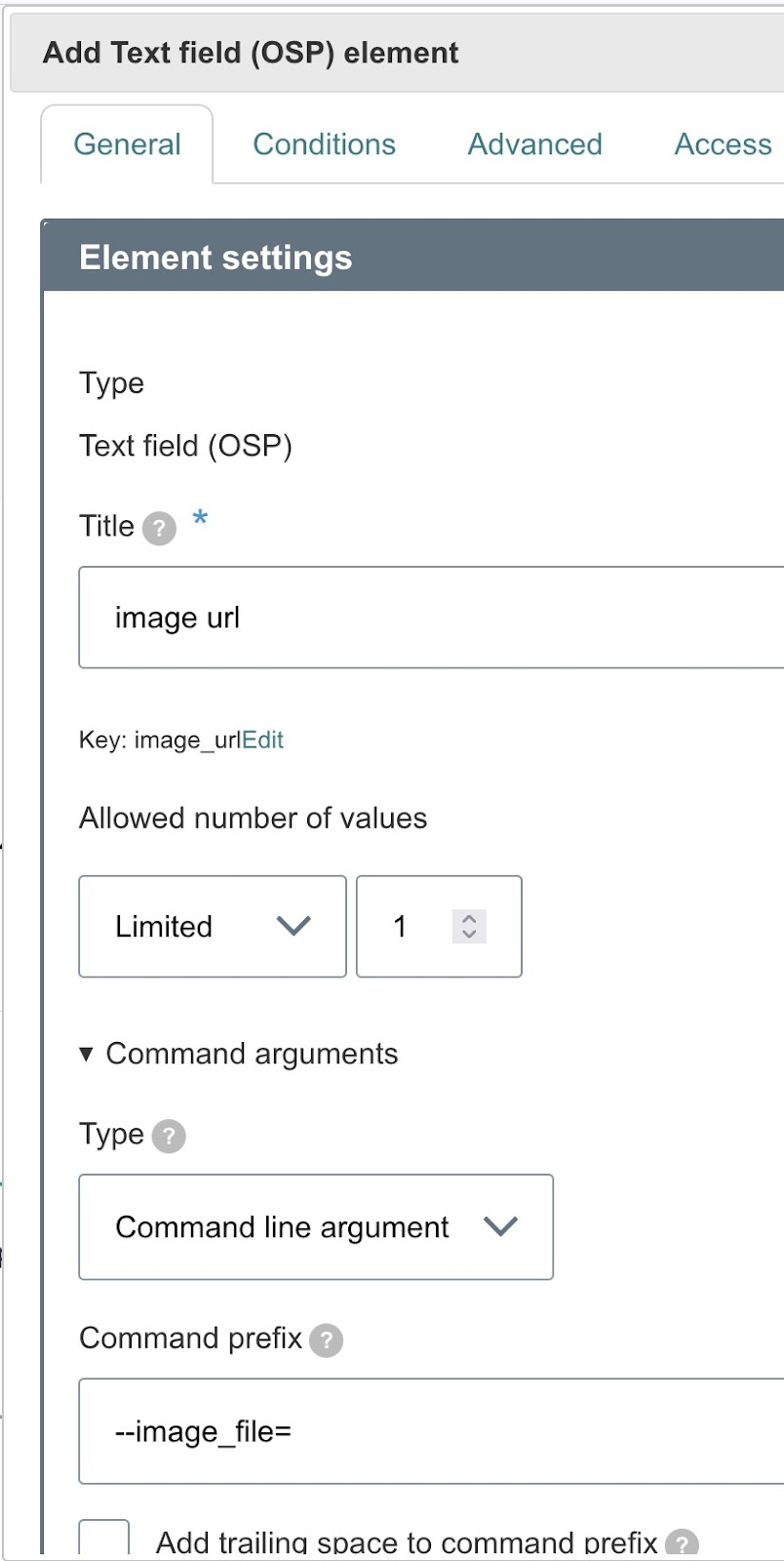
Step 13-4: Add and configure the Text Field ↑
After selecting the text field element, you need to configure it to match your application requirements.
- Title: Enter the title of the input field (e.g., image url). This is how users will know what to input.
- Key: The key is automatically generated based on the title (e.g., image_url).
- Command arguments: This section allows you to define how the input will be passed to the backend. In this case:
- Type: Select Command line argument.
- Command prefix: Set the prefix, for example, --image_file=
- Ensure the Add trailing space to command prefix checkbox is unselected so that the command is formatted correctly.
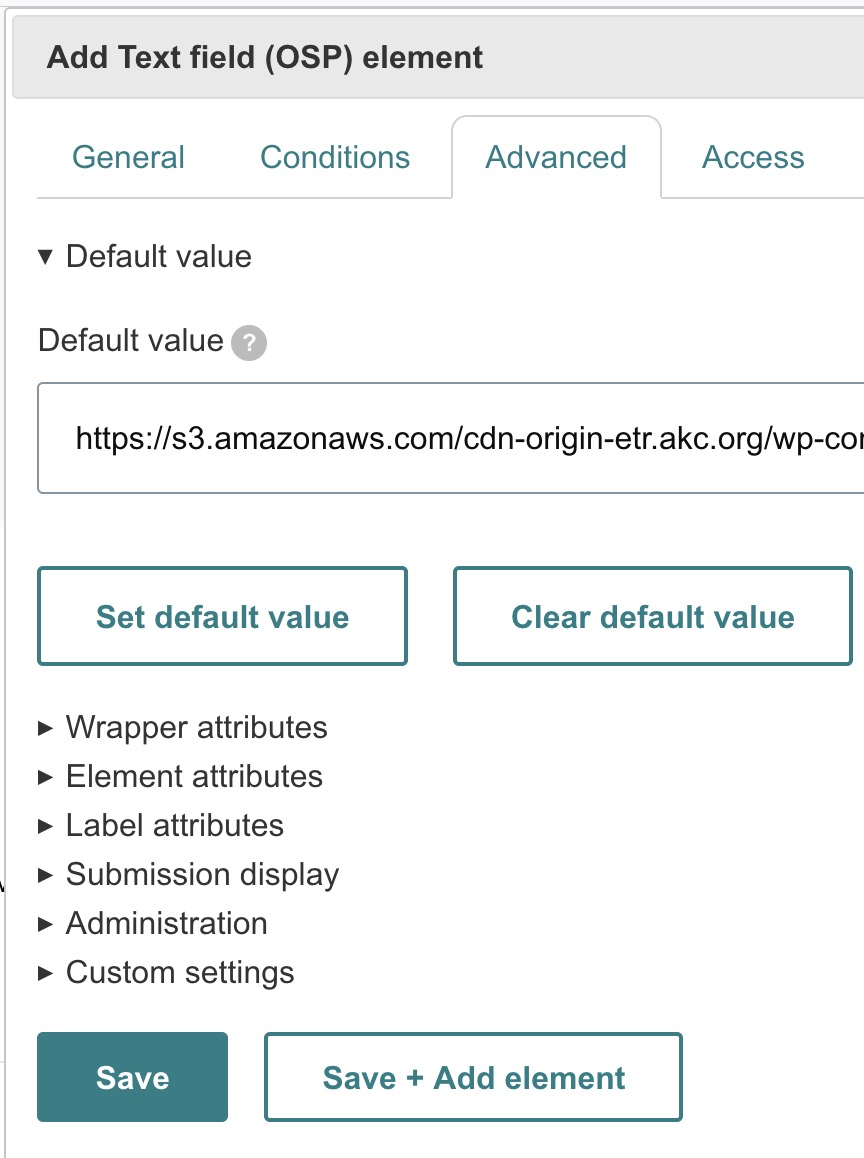
- Default value: You can provide a default value, like the URL of an example image (https://s3.amazonaws.com/cdn-origin-etr.akc.org/wp-content/uploads/2017/11/09152345/Alaskan-Malamut…).
Once everything is configured, click Save to add this element to the form.
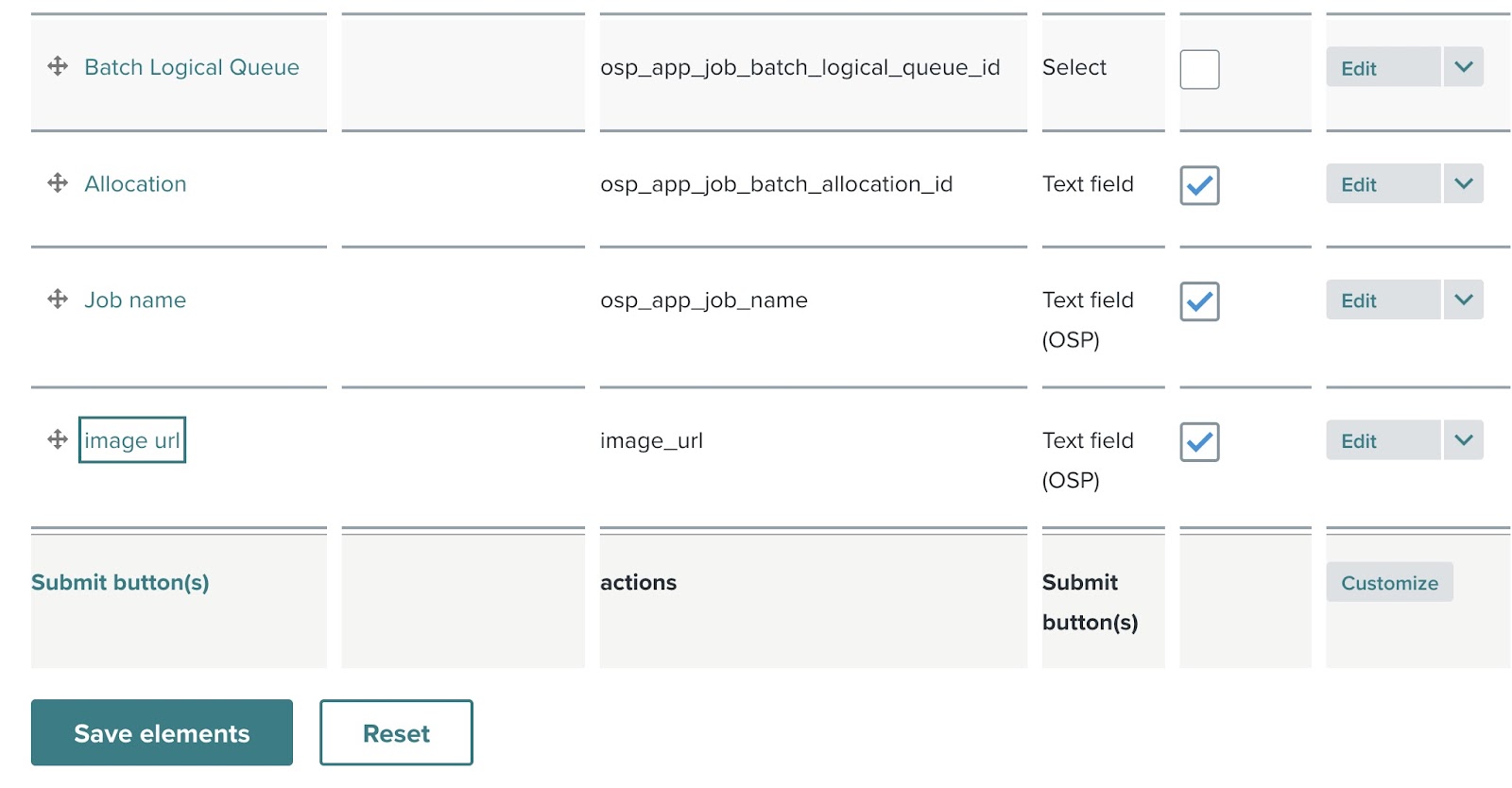
Step 13-5: Review added element ↑
After saving, the newly added text field (image url) will appear in the element list on the right side of the screen. This list shows all the input fields that will be included in the final application form.
At this stage, you can continue adding more elements or adjust the current ones as needed.
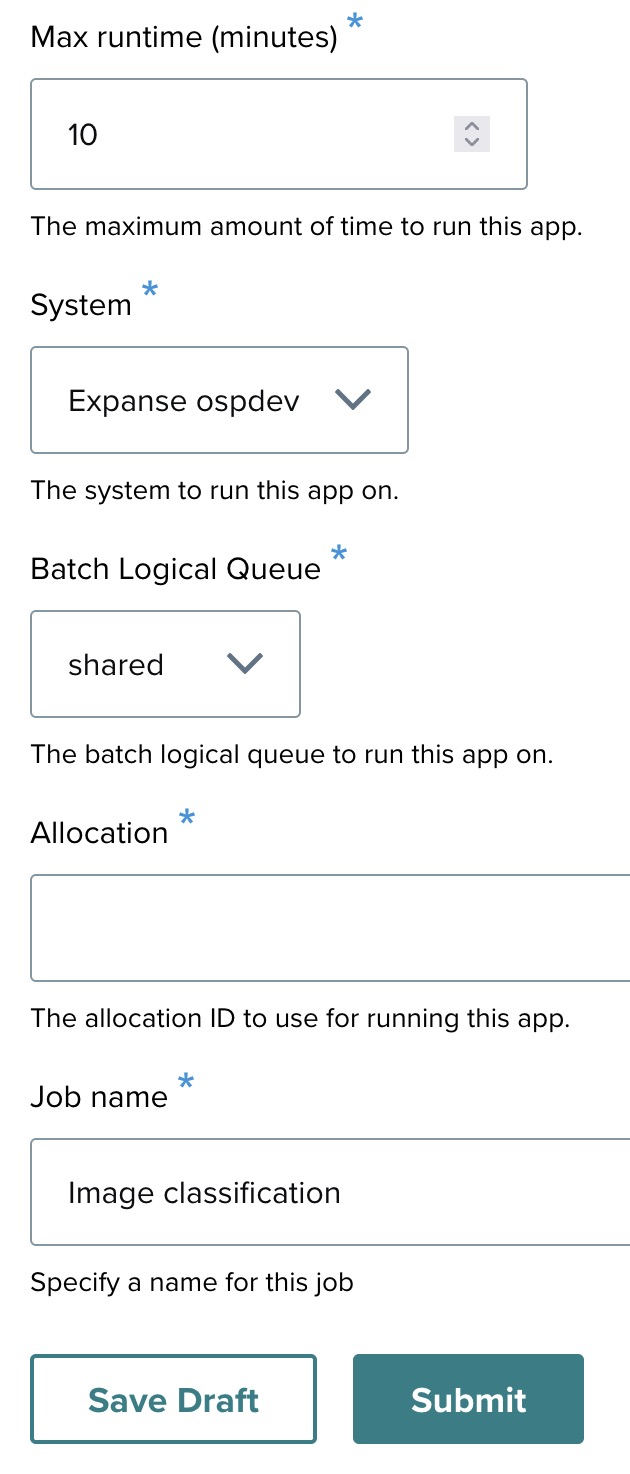
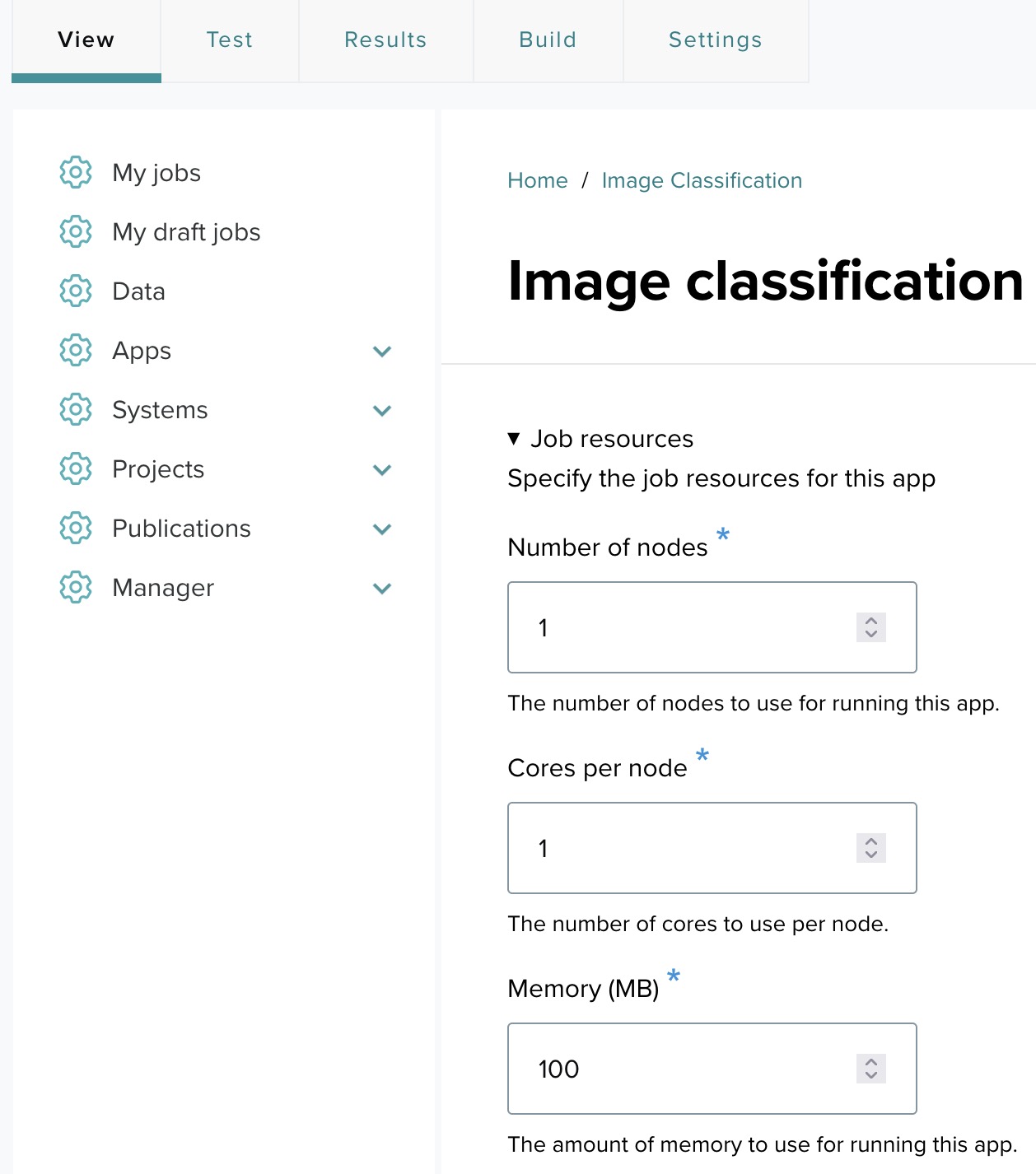
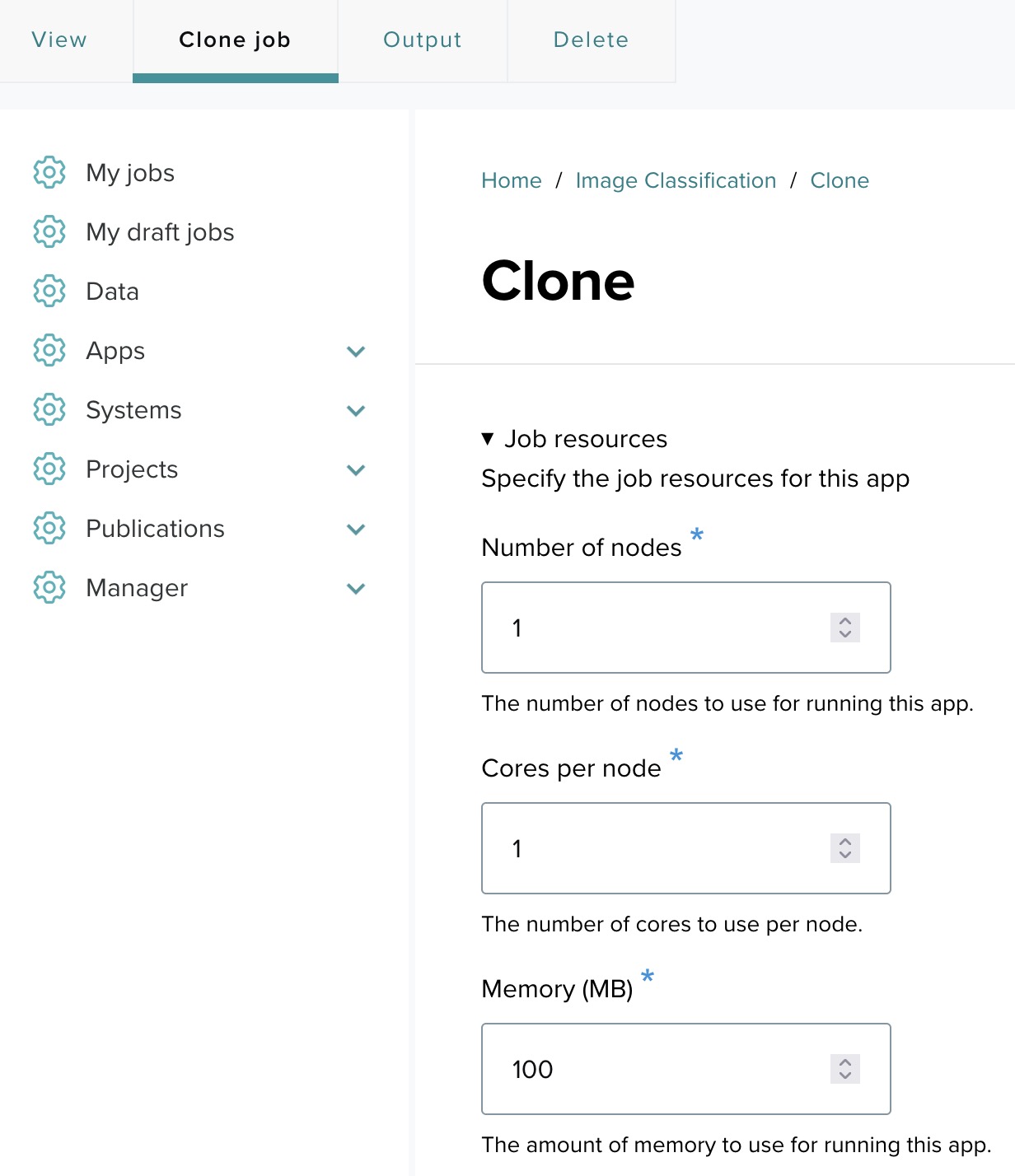
Step 13-6: The final app form ↑
Click the View link in the top left corner. Once you’ve added all necessary input fields, the app form will be complete. In this example, after adding the text field for the image url, it is displayed in the form alongside other app settings.
You may update the following information if necessary:
- Number of nodes: Set this based on how many nodes you want the application to use.
- Cores per node: Specify the number of cores per node.
- Memory (MB): Define the memory requirements.
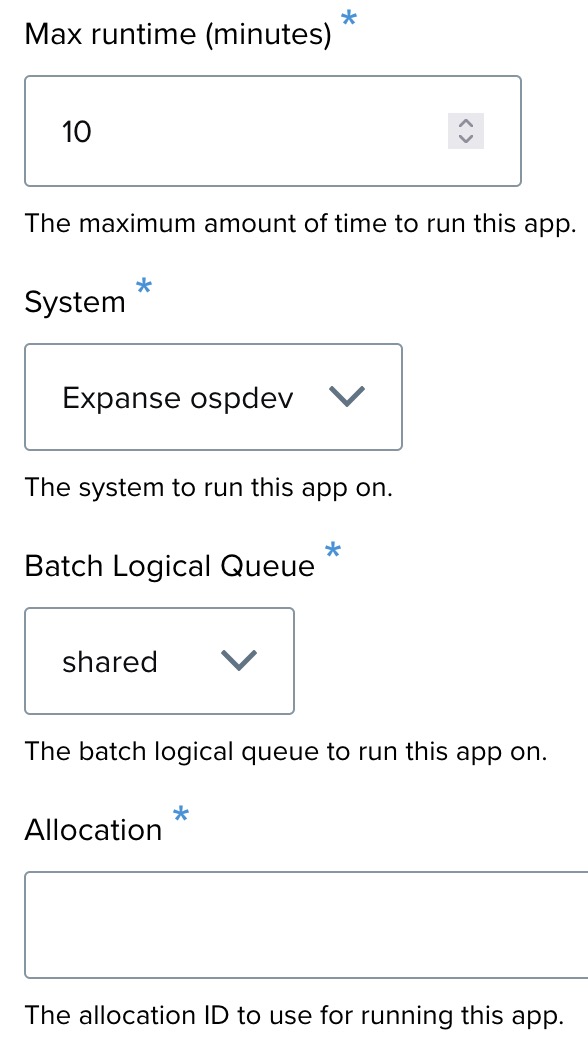
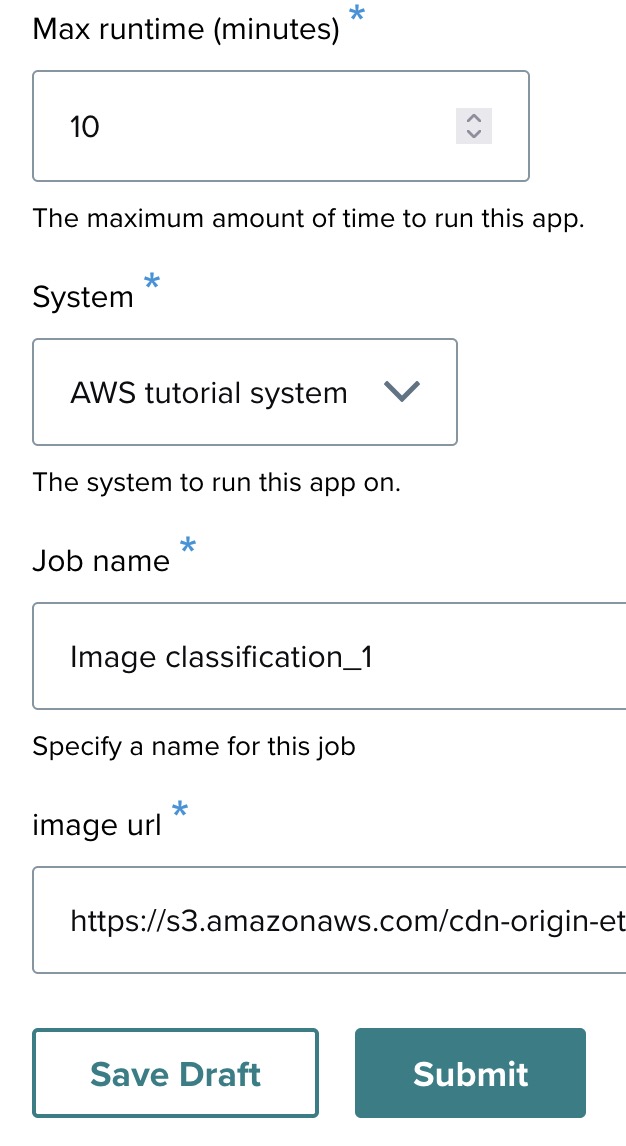
- Max runtime (minutes): Set to 10 minutes.
- System: AWS system or cluster (Expanse service in this case).
- Allocation: This will be provided by the tutorial organizer.
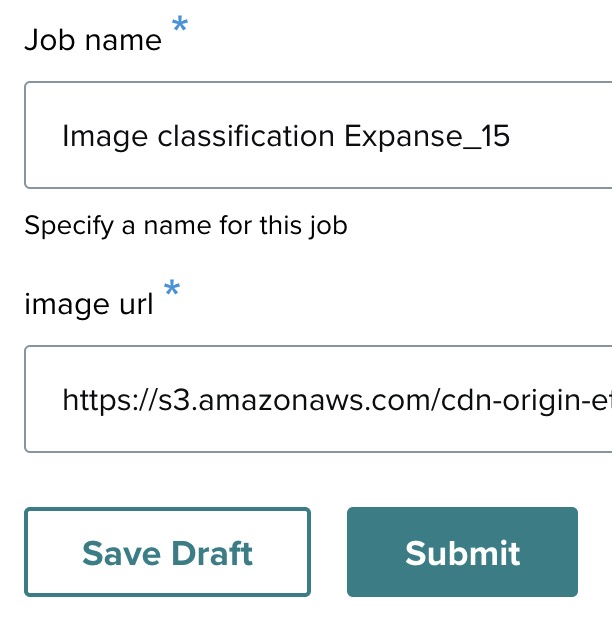
- Job name: Enter a name for this job. In this example, the job name is set as Image classification.
- Image URL: https://s3.amazonaws.com/cdn-origin-etr.akc.org/wp-content/uploads/2017/11/09152345/Alaskan-Malamut…
Once you’ve filled out these details, click "Submit" to proceed, in order to launch the job.
Step 14: Monitoring job status ↑
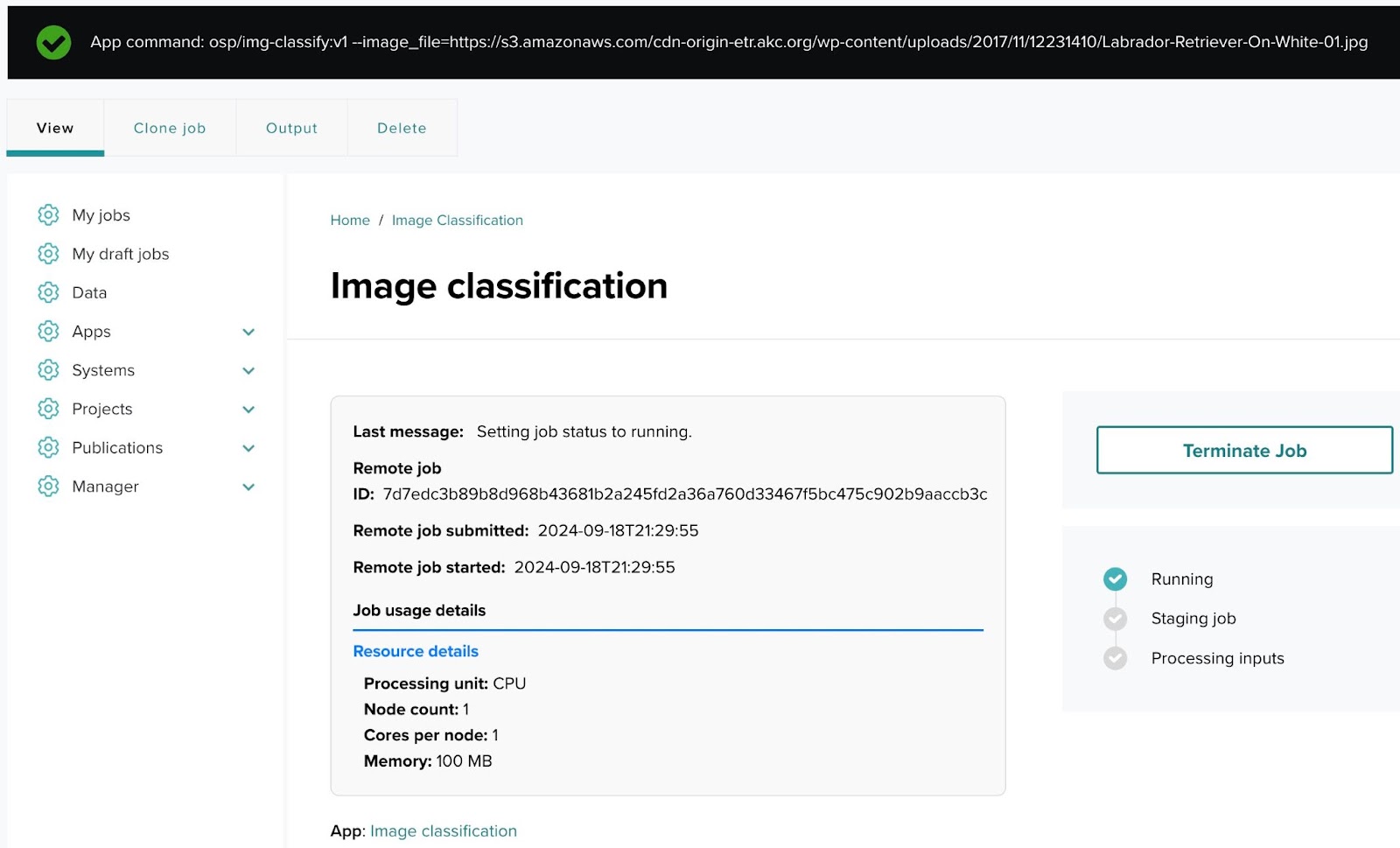
Once the job is submitted, you can monitor its status.
- Job status monitoring:
After launching the job, you will be taken to a status page where you can see the job’s progress. The possible statuses include:- Running: The job is actively being processed.
- Staging job: The job is being prepared for execution.
- Processing inputs: The inputs provided in the submission form are being processed.
- Here, you can also view resource details such as:
- Number of nodes, cores, memory, system name, etc.
- Terminating a job:
If needed, you can terminate the job from this page by clicking Terminate Job.
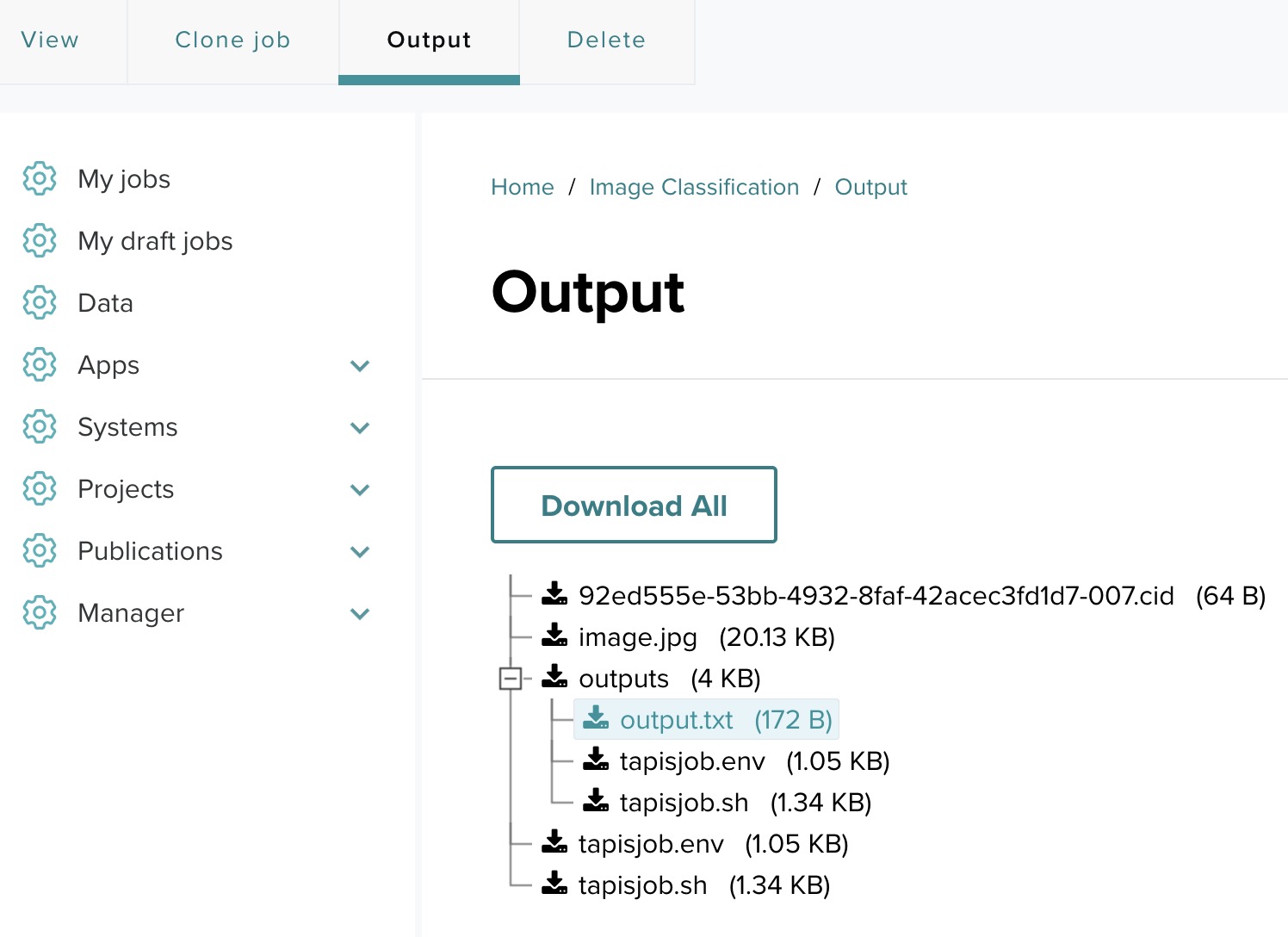
- Reviewing a job output:
You can review the job output from this page by clicking the Output link.
Step 15: Cloning and re-submitting jobs ↑
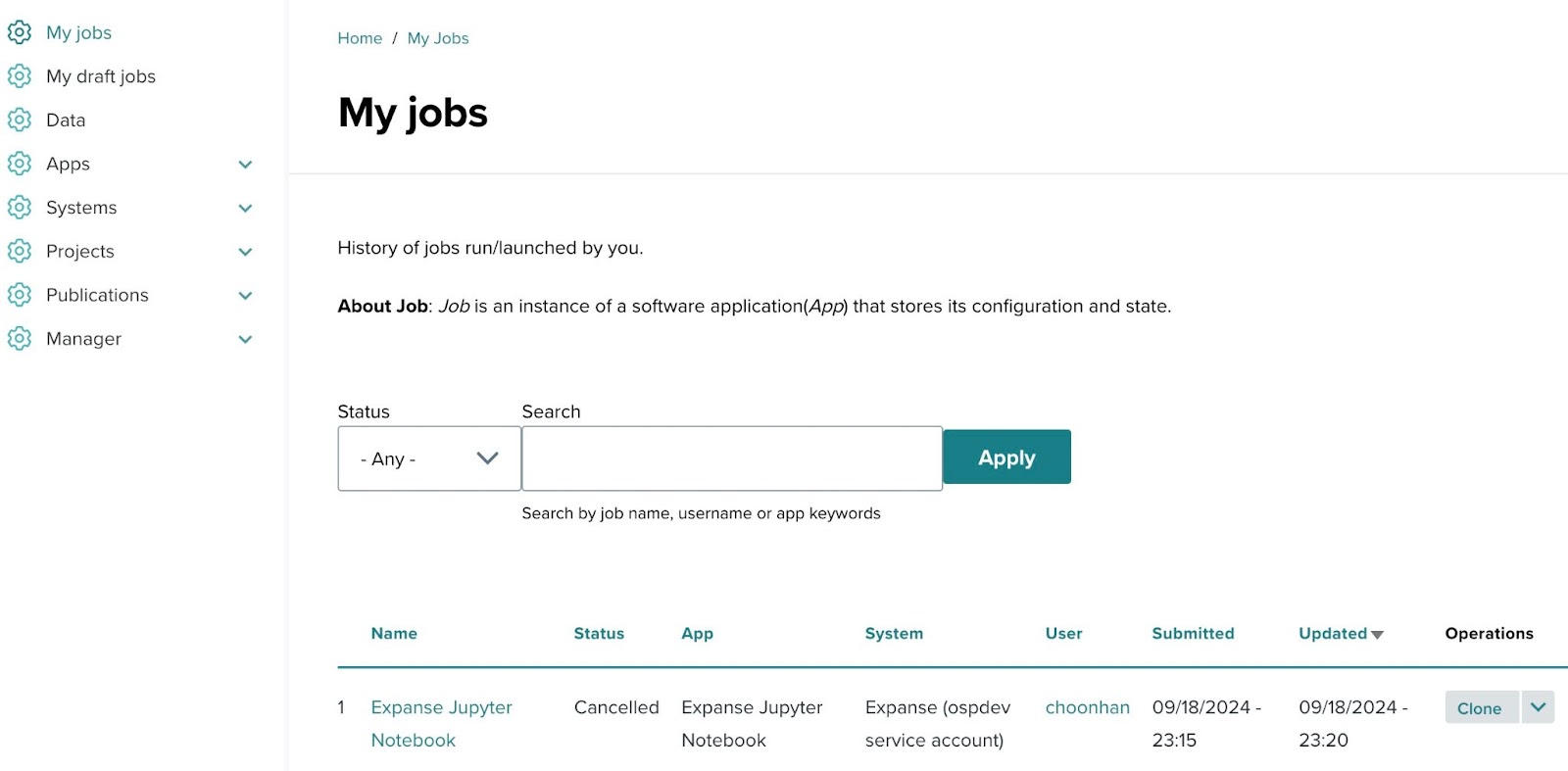
- Accessing previous jobs:
From the My Jobs menu, you can view a list of all jobs that have been submitted. This list shows the job name, application used, system, submission date, and other details. - Cloning a job:
You can clone an existing job by clicking the Clone button next to the job in the list. This will open the job submission page again with all the previously filled parameters.
- Modifying cloned job parameters:
On the cloned job submission page, you can update any of the parameters. For example, you can:- Change the Job name.
- Modify other resource settings if needed.
- Submit or Save Draft:
Once the modifications are made, click Submit to run the cloned job or Save Draft to make adjustments later.
{kind=link}
{kind=link}