Systems
Topics
Overview ↑
In Quakeworx, a system is a hardware resource. It may be a computing or storage resource, which can represent a server or a collection of servers accessible through a single hostname or IP address. Systems are essential components in Quakeworx, enabling users to interact with computational and data resources. Once authorized, user(s) can view available systems and users with additional roles can also create their own system for computing or storage. Currently only compute system is supported.
- Requirements
Must allow SSH auth without passphrase
Must not block connections (whitelisted in firewall)
Tutorial: Creating a System for Science Applications ↑
This guide will walk you through creating a system, which is used to register an execution host and run applications on this system.
Step 1: Accessing the system creation page ↑
- Login to https://qwx1.onescienceway.com.
- Navigate to the "Systems" section, https://qwx1.onescienceway.com/node/add/tapis_system.
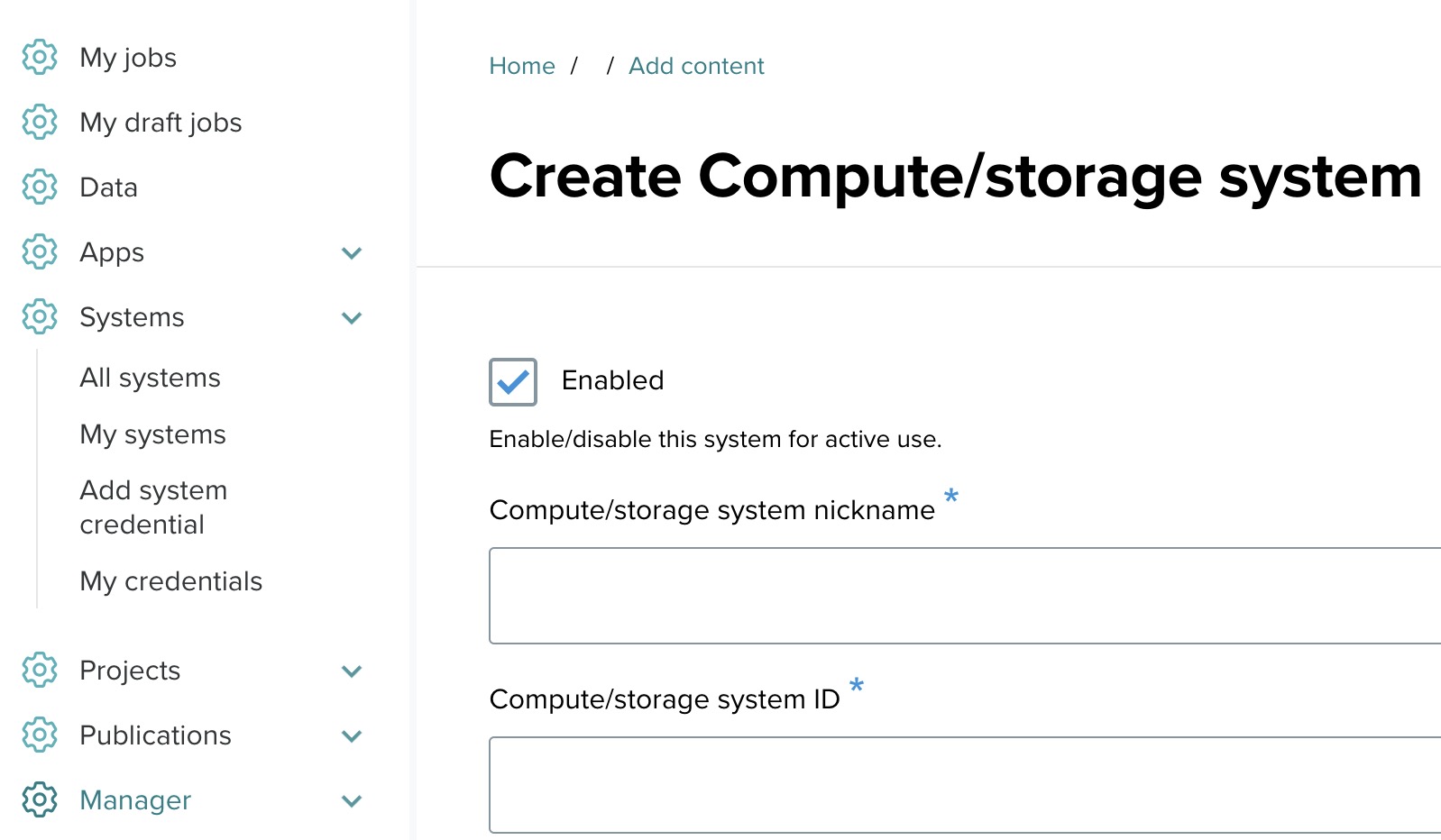
Step 2: Fill out the system form ↑
You will see a form that needs to be filled out to register your system. Follow the instructions below to complete the form:
General information ↑
- Enabled: Make sure the "Enabled" box is checked to activate this system for use.
- Compute/storage system nickname: Provide a recognizable name for the system. In this example, use AWS System.
- Compute/storage system ID: Enter a unique identifier for the system, such as qwx.tutorial.aws.tapis_system.v2. This field only allows lowercase characters without any spaces, and it cannot be changed later.
- Summary: Add a brief summary, for example: An EC2 system for running jobs. This is just for reference.
- Description: Provide additional details about the system if necessary. You can leave this blank or add more information about the system configuration.
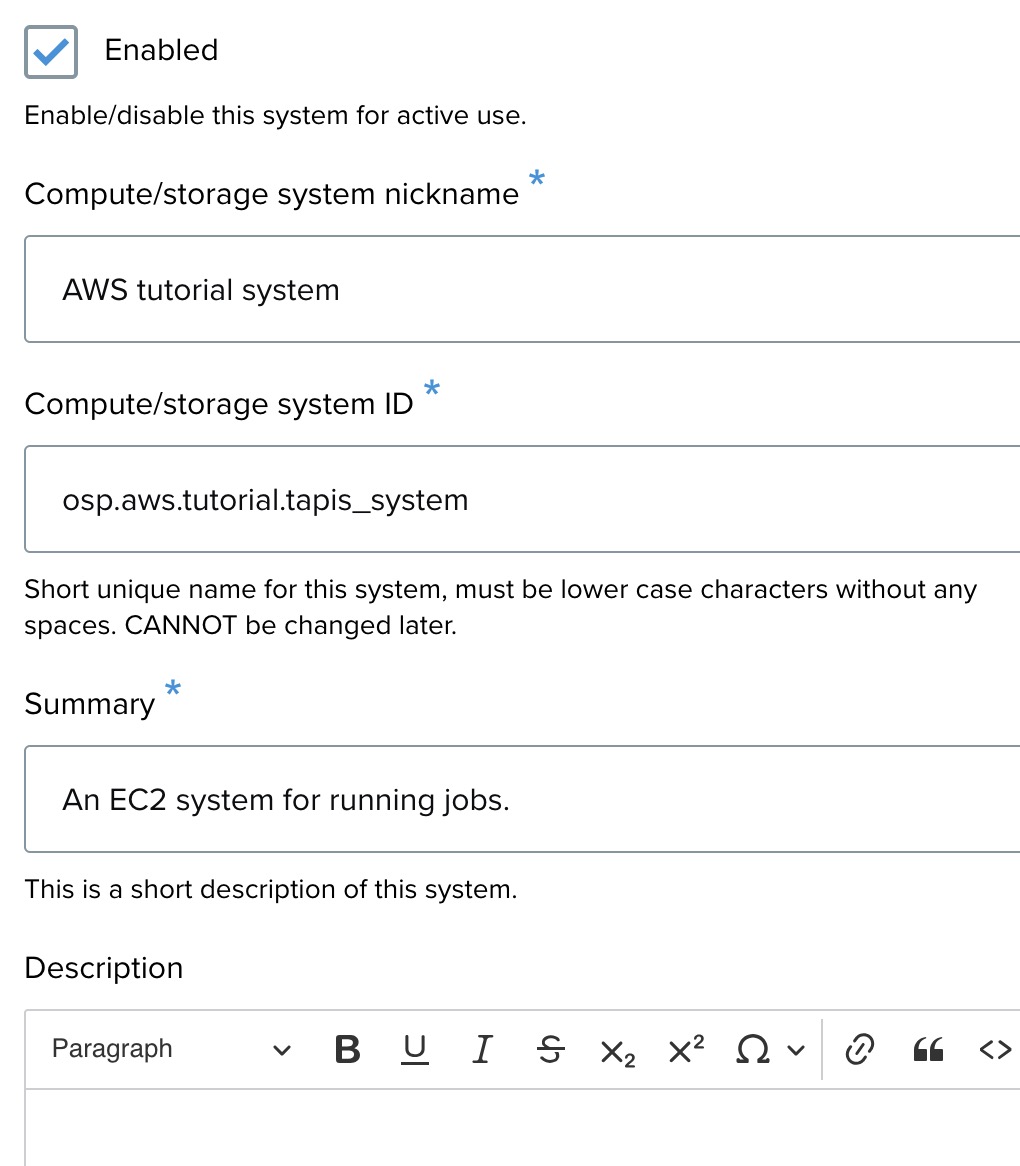
Connection details ↑
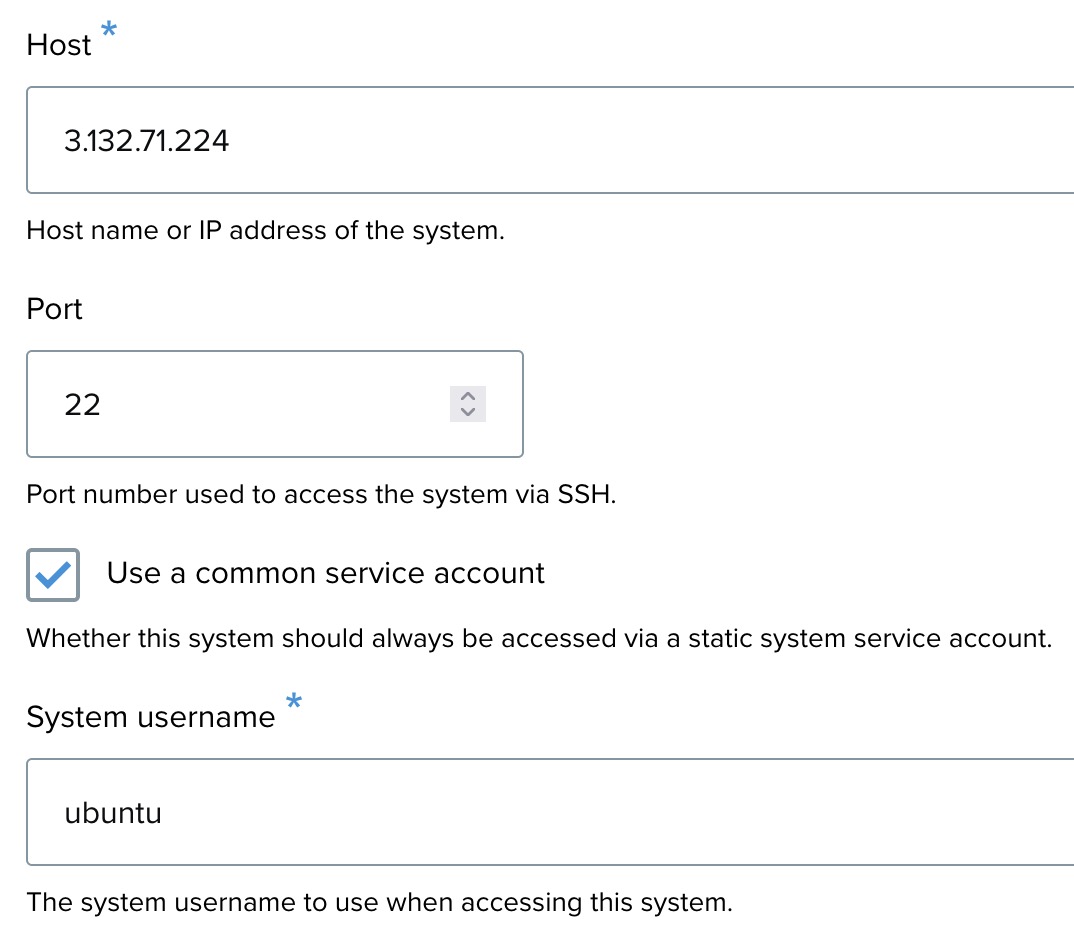
- Host: Enter the IP address or hostname for the system. For example: 75.183.82.136.
- Port: Enter the port used to connect to the system. The default SSH port is 22.
- Use a common service account: Check this box to ensure that the system is accessed via a static system service account. For example: ubuntu
System type ↑
- System type: Select Linux - Single host or a batch cluster if this system is based on Linux and meant for job execution. The other options are for storage systems like S3, iRODS, or Globus.

Root directory ↑
- Root directory: Specify the root directory of the system, where jobs will run. In this case, use /home/ubuntu/tapis_system.

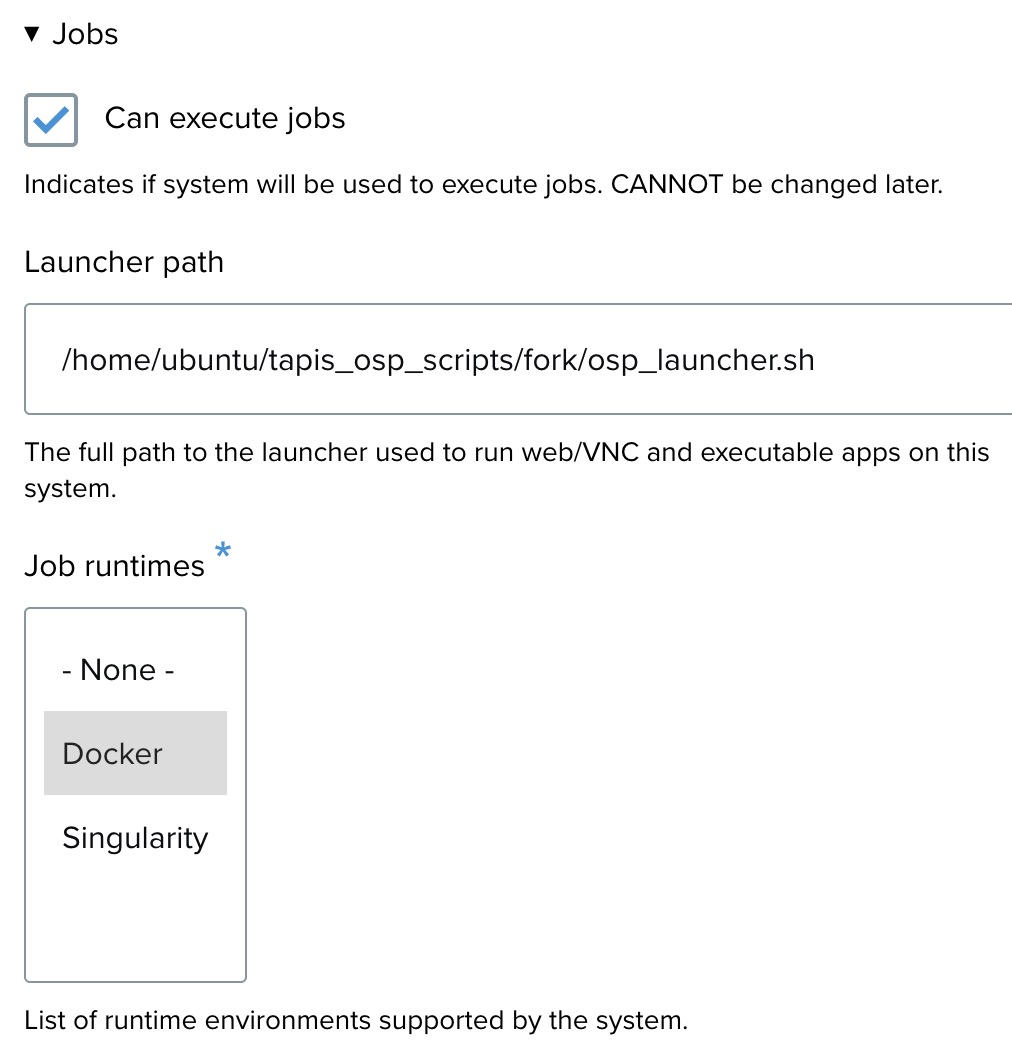
Jobs settings ↑
- Can execute jobs: Ensure this box is checked, as the system will be used to run jobs.
- Launcher path: Specify the path to the launcher script that will be used to run jobs. Example: /home/ubuntu/tapis_osp_scripts/fork/osp_launcher.sh.
- Job runtimes: Choose between Docker and Singularity for the runtime environment. In this example, select Docker.
Job working directory ↑
- Job working directory: Enter the working directory where jobs will run. You can use the placeholder path /users/${JobOwner}, which dynamically creates the path based on the job owner.

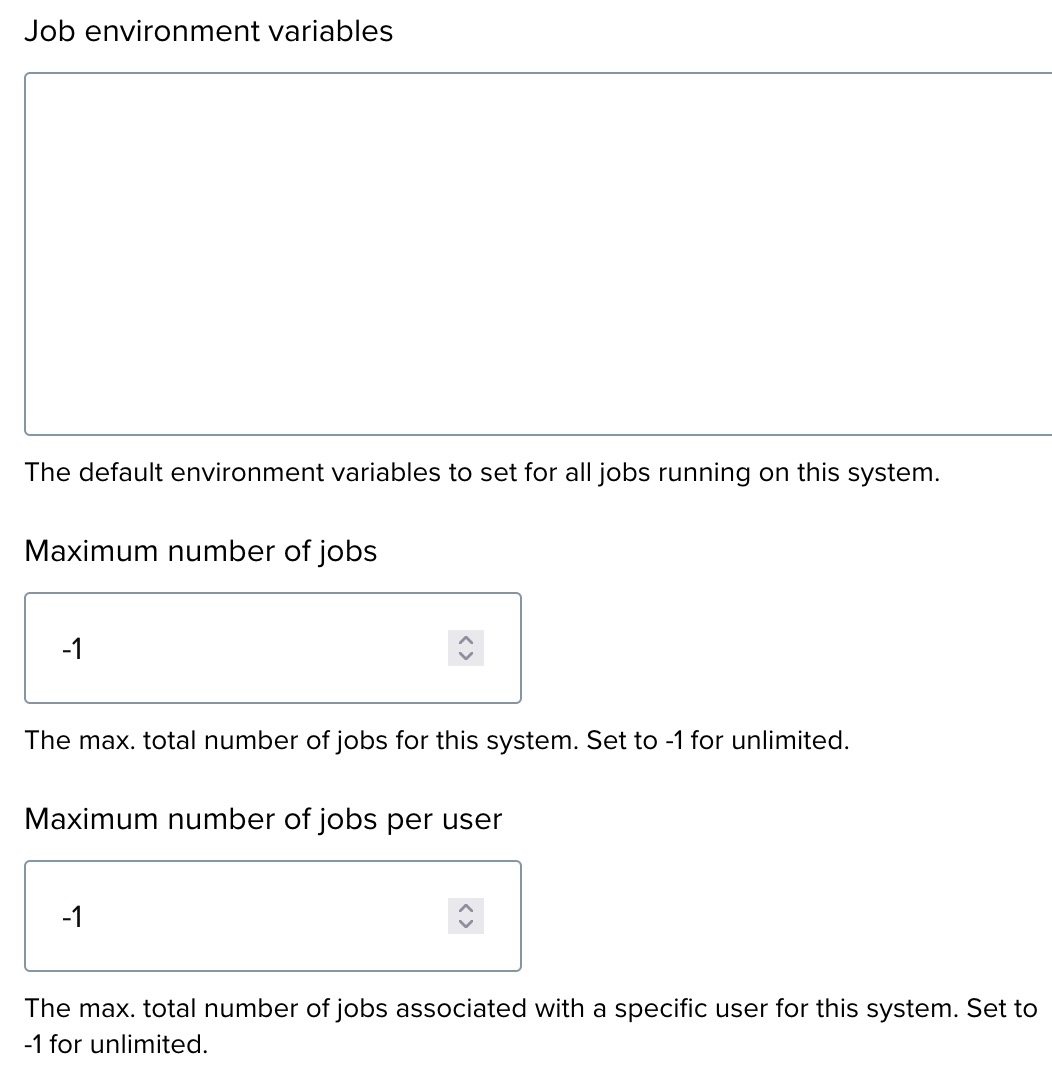
Job environment variables ↑
- Job environment variables: This section allows you to define default environment variables for all jobs on this system. If not needed, you can leave this blank.
- Maximum number of jobs: Define the maximum number of jobs allowed. Set this to -1 for unlimited jobs.
- Maximum number of jobs per user: Set the maximum number of jobs per individual user. Use -1 for unlimited jobs per user.
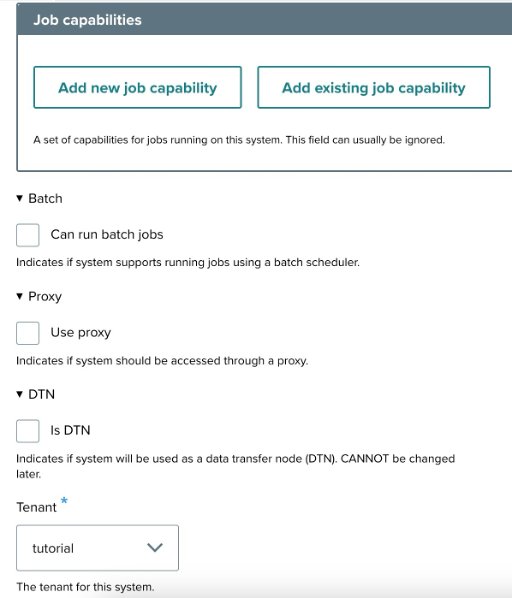
Additional settings: ↑
- Job capabilities: You can add job capabilities if required by clicking the "Add New Job Capability" or "Add Existing Job Capability" button. These fields can usually be ignored unless you have specific job requirements.
- Batch: Select this if you need to run batch jobs using a scheduler.
- Proxy: Check this if the system requires a proxy for access.
- DTN: If the system will be used as a data transfer node, check this box.
- Tenant: Choose the tenant under which this system will run. For example, select Quakeworx from the dropdown menu.
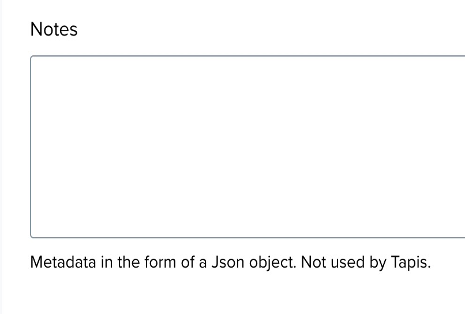
Notes ↑
- Notes: Optionally, you can add metadata or additional information in JSON format. This field is not required by Tapis, but it can be helpful for organization purposes.
Step 3: Finalize and save ↑
- After completing the form, review all the details to ensure correctness.
- Click on the Save button to register the system.
Tutorial: Creating System Credential for the System ↑
This guide will walk you through the final step of completing the setup for your system by creating a system credential. This credential is necessary to register the execution host for running science applications on the system.
Prerequisites: ↑
- System: Ensure you have already created the system (e.g., AWS system).
- SSH Access: You will need to access your system using SSH to add the public key to your authorized_keys file.
Step 1: Add a system credential ↑
Once the system is created, you will be prompted to add credentials for it. This is required for system access.
- Access the credential creation page:
- Navigate to the “Systems” menu, https://qwx1.onescienceway.com/tapis/system-credential/add, and click "Add system credential."
- Select the System:
- Under the System dropdown menu, select the compute/storage system you just created. In this case, select AWS system.
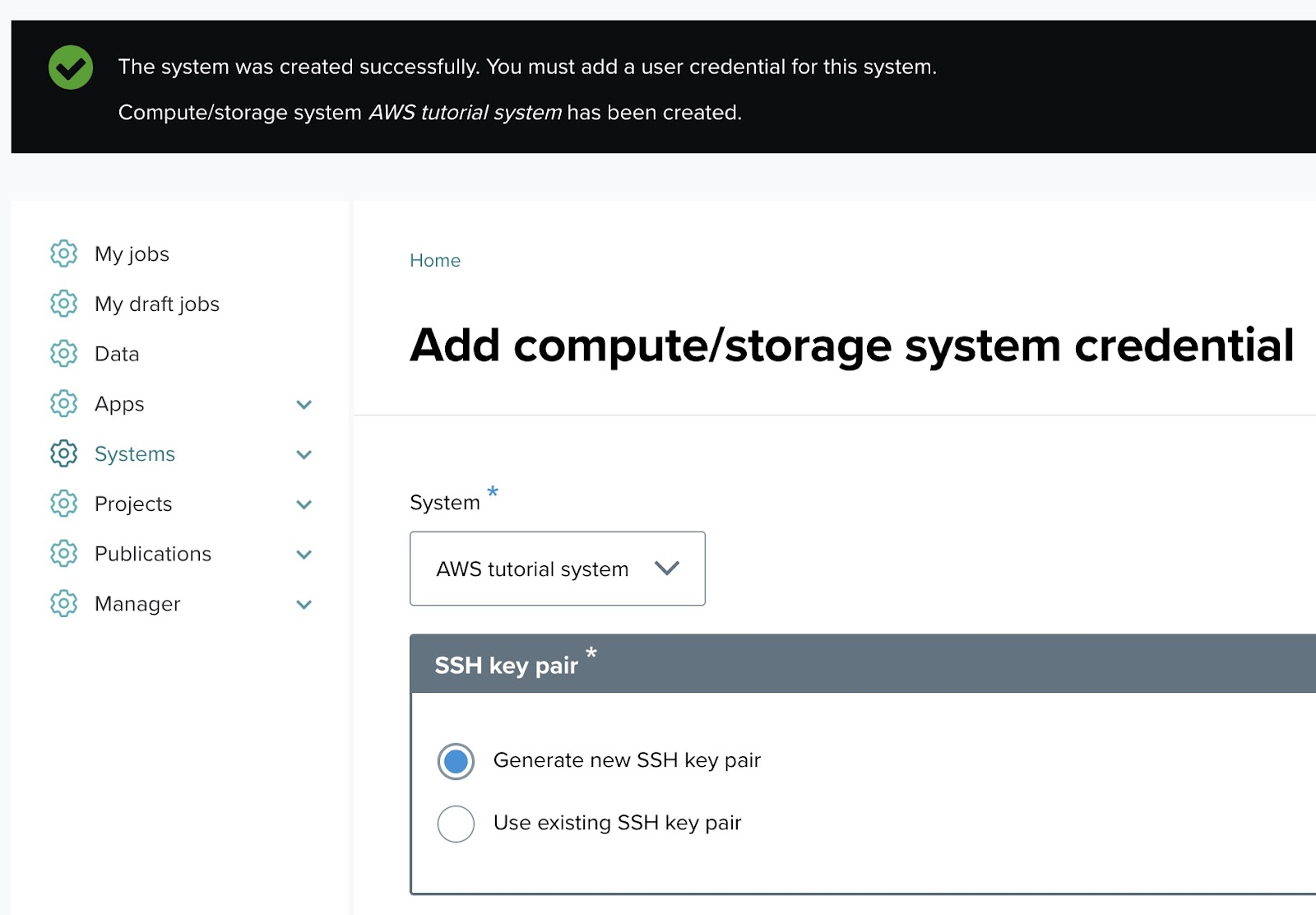
Step 2: Fill out the system credential form ↑
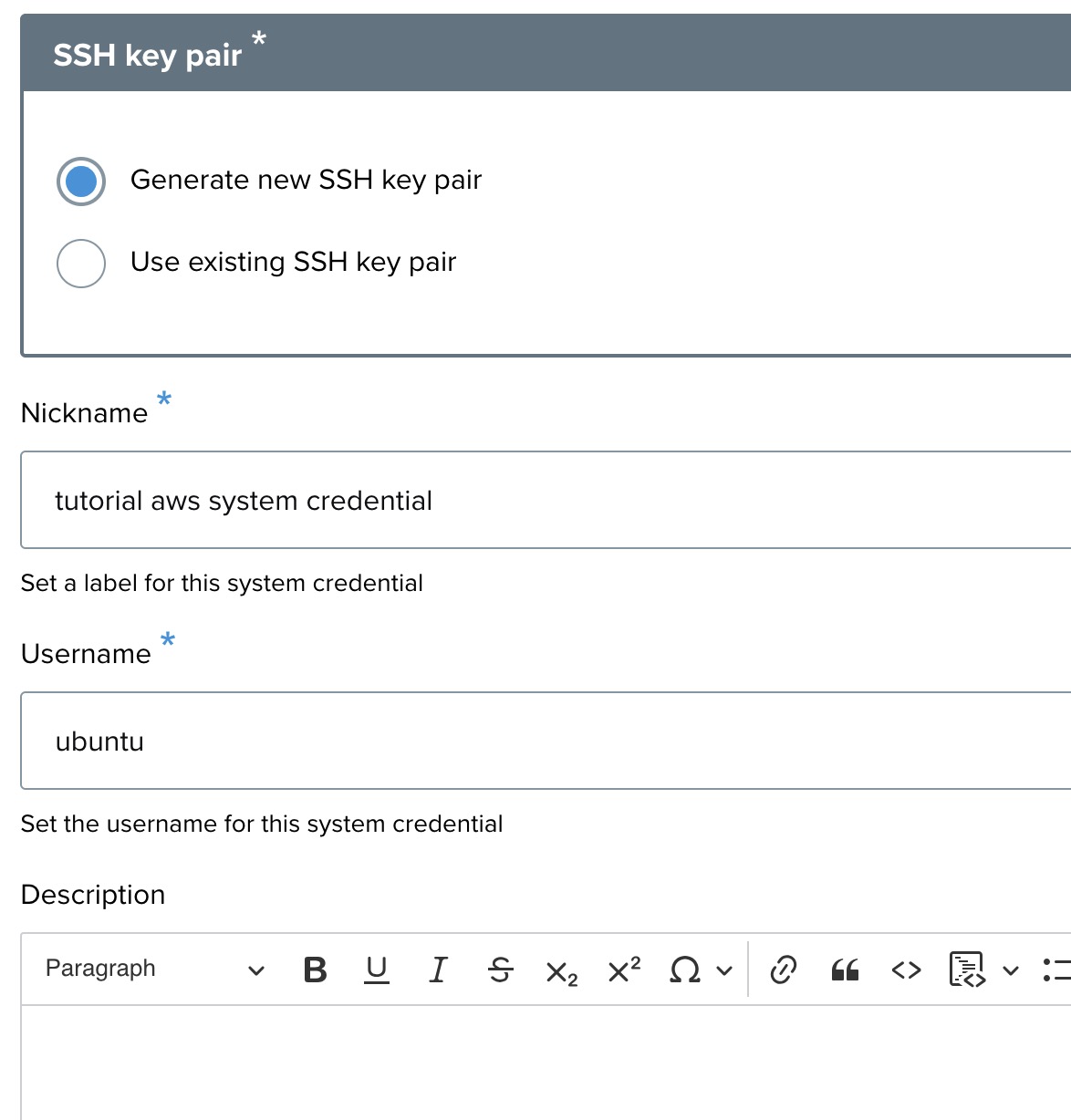
SSH key pair ↑
You have two options for the SSH key pair:
- Generate new SSH key pair: If you want the system to create a new SSH key for secure access, select this option (default).
- Use existing SSH key pair: If you already have an SSH key, select this option and provide the public key.
Credential nickname ↑
- Nickname: Provide a recognizable nickname for this credential, such as aws tutorial credential. This helps differentiate between multiple credentials if needed.
Username ↑
- Username: Enter the username you will use to access the system. For example, in this case, use ubuntu.
Description ↑
- Description: Optionally, you can provide a description for the credential. This can be left blank or used to add extra information about the credential purpose.
In this case, the form defaults to generating a new SSH key pair, which is the recommended option.
Step 3: Add the public key to the system’s authorized_keys ↑
After saving the credential, you will see the following information displayed:
- System: The system you selected (e.g., AWS system).
- Username: The username you entered (e.g., ubuntu).
- Public key: A newly generated public SSH key that will be used to authenticate your connection to the system.
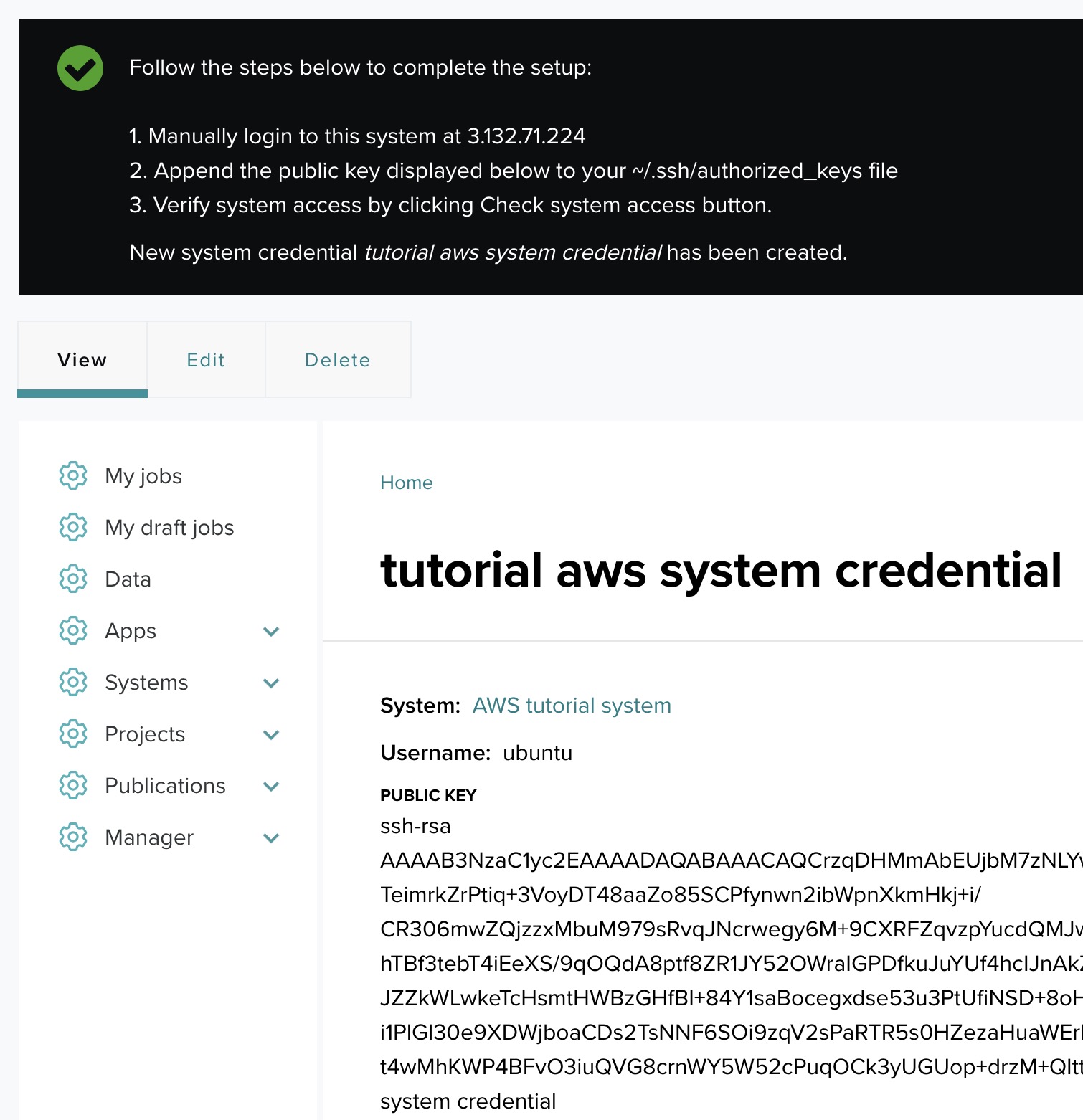
Follow the steps below to complete the setup: ↑
- Manually login to your system at the specified host IP (e.g., 78.183.82.136).
- Append the public key to your ~/.ssh/authorized_keys file on the system:
- Open the ~/.ssh/authorized_keys file on your remote system.
- Copy and paste the provided public key into this file.
- Save and close the authorized_keys file.
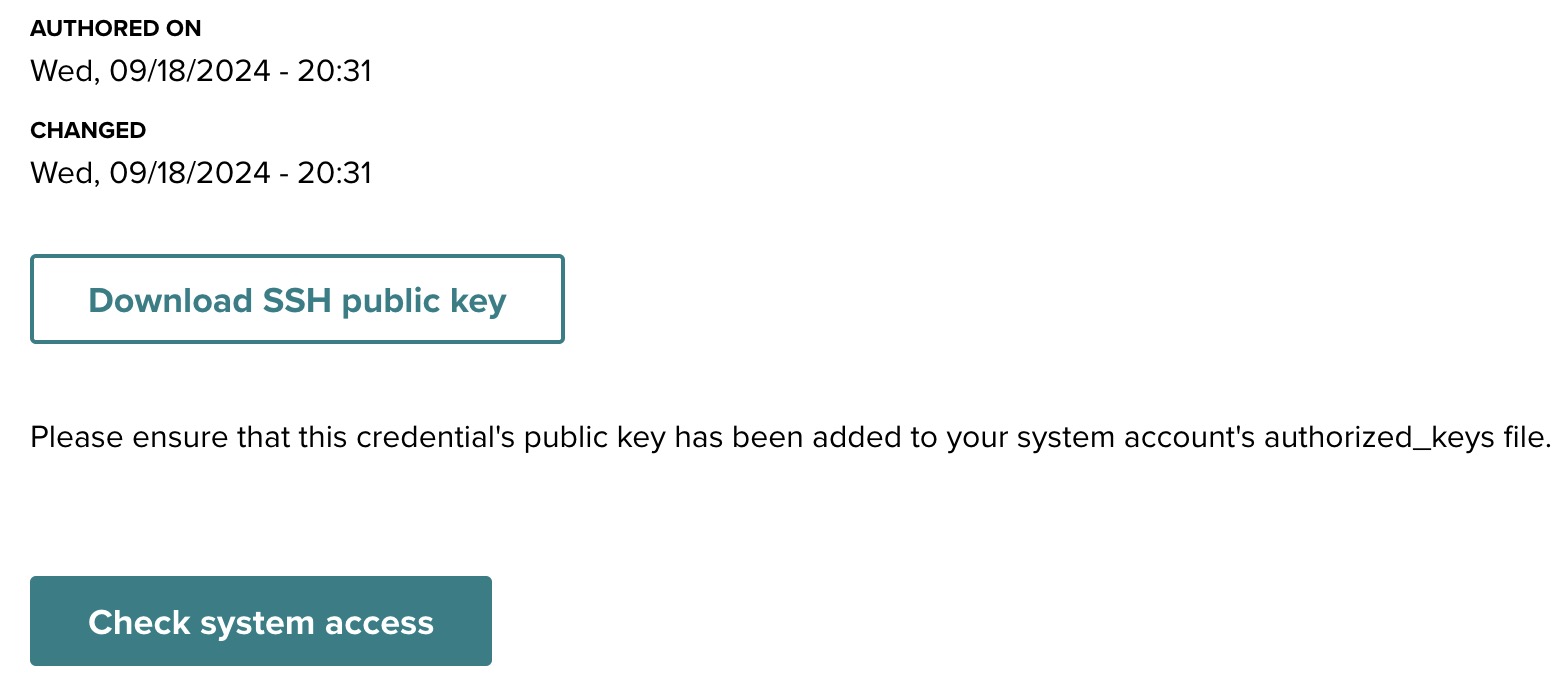
Step 4: Verify system access ↑
Once the public key is added to the authorized_keys file, return to the system credential interface and:
- Click the Check system access button to verify that the system is accessible with the newly created credential.
If everything is configured correctly, you should receive a confirmation that the system is accessible and the system credential creation is complete.
Additional resources ↑
- Download SSH public key: If needed, you can download the public key from the system credential page for future use.
- Troubleshooting: Ensure that the SSH public key is correctly copied to the authorized_keys file and that file permissions are properly set (chmod 600 ~/.ssh/authorized_keys).
Tutorial: Batch app configuration to run job on a HPC system ↑
This tutorial guides you through setting up a system for batch processing. You'll learn how to configure batch queues, define scheduler profiles, and manage proxy settings or Data Transfer Nodes (DTNs). The interface offers flexibility for configuring job parameters, module loading, and MPI commands.
Step 1: Batch job settings ↑
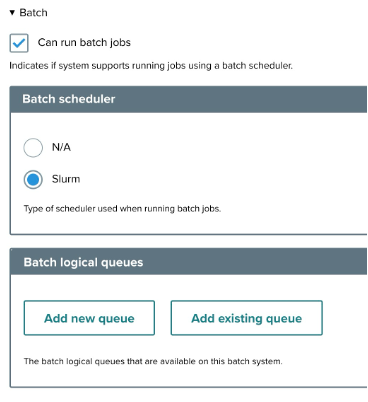
- Can run batch jobs: Checkbox indicating whether the system supports batch job execution through a scheduler.
- Batch scheduler: Select the appropriate scheduler for your system from the following options:
- N/A: Default option if no batch scheduler is used.
- Slurm: A specific batch scheduling system.
- Batch logical queues: Manage the logical queues for job submission with these options:
- Add new queue: Create a new queue.
- Add existing queue: Use a pre-existing queue.
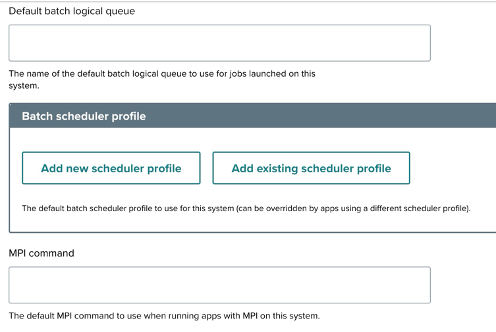
- Default batch logical queue: Input the default queue for jobs on the system.
- Batch scheduler profile: Manage profiles to customize the scheduling of jobs:
- Add new scheduler profile: Create a new scheduler profile.
- Add existing scheduler profile: Use an existing scheduler profile.
- MPI command: Specify the default MPI command for running MPI applications.
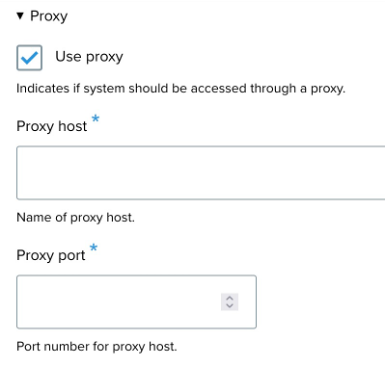
- Proxy Settings:
- Use proxy: Checkbox to enable the use of a proxy for the system.
- Proxy host: Enter the proxy server's host address.
- Proxy port: Enter the proxy server's port number.
Step 2: Adding a batch logical queue ↑
To create a new batch queue, fill in the following fields:
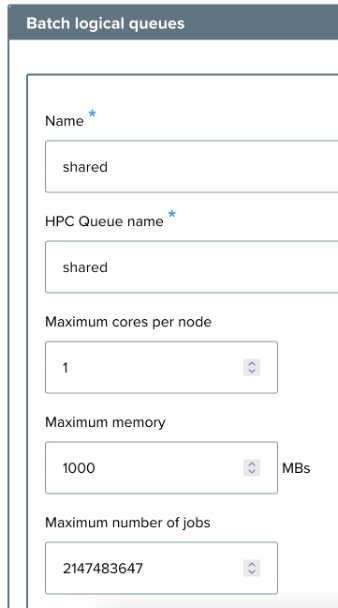
- Name: The name of the new queue (e.g., shared).
- HPC Queue name: The name of the queue as recognized by the High-Performance Computing system.
- Maximum cores per node: The maximum number of cores per node (e.g., 1).
- Maximum memory: The maximum allowable memory for jobs in this queue, in MB (e.g., 1000).
- Maximum number of jobs: Limit the total number of jobs allowed in the queue.
- Maximum number of jobs per user: Set a limit on the number of jobs a single user can submit (e.g., 2147483647).
- Maximum number of nodes: The maximum number of nodes that a job in this queue can use (e.g., 1).
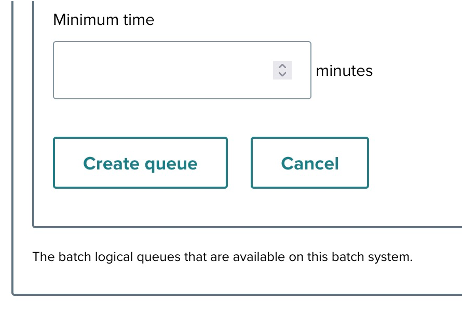
- Maximum time: Set the maximum time for a job to run in this queue, in minutes (e.g., 10).
- Minimum cores per node: The minimum number of cores required per node.
- Minimum memory: The minimum required memory for jobs in the queue, in MB.
- Minimum number of nodes: The minimum number of nodes required for a job.
- Minimum time: The minimum time a job must run in this queue.
Use the Create queue button to finalize the setup or Cancel to discard it.

Step 3: Batch scheduler profile ↑
Create and configure a scheduler profile to customize how jobs are handled:
- Scheduler profile nickname: A descriptive name for the scheduler profile (e.g., Expanse scheduler profile).
- Scheduler profile ID: A unique identifier for the profile (e.g., qwx1.tutorial.expanse.sched.profile).
- Description: Provide a brief description of the profile's purpose (e.g., Scheduler profile for Expanse).
- Tenant: Select the relevant tenant from the dropdown menu (e.g., Quakeworx).
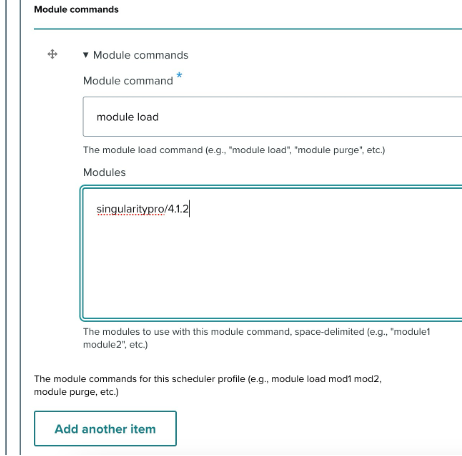
- Module commands: Define any commands related to module loading:
- Module command: Specify the command (e.g., module load).
- Modules: Enter the module to be loaded (e.g., singularity:latest).
- Use the Add another item button to include more commands as needed.

Step 4: Data Transfer Node (DTN) system ↑
DTN systems are used to manage the transfer of files between nodes, providing an alternative system for file handling.
- DTN system: Choose whether to configure a Data Transfer Node:
- Add new node: Create and configure a new DTN system.
- Add existing node: Select a previously configured DTN system.